# KNIME服务器管理指南
# 介绍
本指南详细介绍了KNIME Server的配置选项。
如果要安装KNIME Server,则应首先查阅《 KNIME Server安装指南》 (opens new window)。
有关配置KNIME WebPortal的管理选项,请参阅《 KNIME WebPortal管理指南》 (opens new window)。
有关从KNIME Analytics Platform连接到KNIME Server或使用KNIME WebPortal的指南,请参考以下指南:
其他资源也是《 KNIME服务器高级设置指南》 (opens new window)。
# 发行说明
KNIME Server 4.11是4.x发行版的功能发行版。使用KNIME Server 4.10的所有客户端将继续不受限制地使用KNIME Server 4.11。
| 要了解当前正在运行哪个版本的KNIME Server,可以 在WebPortal上查看“ 管理”页面 (opens new window)。 | |
|---|---|
# 新的功能
有关包含新的Analytics Platform 4.2功能的列表,请参见此处 (opens new window)。
突出的新功能是:
- 改进的OAuth身份验证(设置指南) (opens new window)
- 执行器组(新功能) (opens new window)
- 执行器预订(新功能) (opens new window)
- 在AWS上自动缩放(AWS指南) (opens new window)
- 切换到Apache Tomcat(通过TomEE)(发行说明) (opens new window)
还提供了KNIME Server 4.11的 (opens new window)详细变更 (opens new window)日志。
# 切换到Apache Tomcat
在以前的版本中,KNIME Server的应用程序服务器组件基于Apache TomEE(Apache Tomcat的Java Enterprise Edition)。现在,在新的KNIME Server 4.11中,将TomEE替换为标准的Apache Tomcat。
与切换到标准Apache Tomcat一致,现在不鼓励使用旧的EJB挂载点连接到KNIME Server,而支持较新的REST实现。迁移到REST挂载点非常简单。用户使用现有的EJB挂载点登录后,将立即提示您单击即可切换到REST。与EJB相比,REST提供了许多好处-特别是在性能和稳定性方面。
使用的Tomcat版本是9.0.36。请注意,对于不愿切换到Tomcat的现有客户,我们仍然提供基于Apache TomEE的KNIME Server安装程序。它已更新到最新版本,TomEE 8.0.3。
# 通过Qpid执行
早期版本的KNIME Server使用RMI在应用程序服务器和KNIME Executor之间建立连接。RMI现在已由基于Apache Qpid的嵌入式消息队列代替。诸如消息请求作业执行之类的事件不是通过应用程序服务器与执行器之间直接通信,而是通过消息队列传递。
Qpid技术与KNIME Server安装程序捆绑在一起,因此不需要其他设置。所有新安装的KNIME Server安装都配置为默认使用Qpid。另外,KNIME Server安装程序对执行器的knime.ini文件进行了各种调整,以简化与Qpid的连接。
请注意,Qpid仅支持与应用程序服务器在同一主机上运行的单个KNIME Executor。如果您要运行多个分布式KNIME执行器,仍然需要设置RabbitMQ。与以前的版本不同,Executor不会与服务器一起自动启动,而是必须单独启动。《KNIME服务器安装指南》 (opens new window)中介绍了必要的步骤
# 切换到REST挂载点
从KNIME Server 4.11发行版开始,现在不鼓励使用旧的EJB挂载点连接到KNIME Server,而支持较新的REST实现。如果是基于Tomcat的KNIME服务器,这将是唯一有效的连接方法。即,在Apache Tomcat上运行的KNIME服务器不再支持EJB。
我们已经非常容易地迁移到REST挂载点。只需使用现有的EJB挂载点登录,就会出现提示,您可以单击一下即可从其切换到REST。与EJB相比,REST提供了许多好处-特别是在性能和稳定性方面。
切换到REST之后,您会注意到行为上有些细微的差别。最值得注意的是,当您启动使用Workflow Variables或的工作流程时,我们不再显示弹出对话框Workflow Credentials。现在,可以直接从工作流执行对话框访问这些选项。要到达那里,请右键单击服务器存储库中的工作流程→执行。然后打开Configuration options选项卡。这使您可以输入工作流变量和工作流凭证。
此外,该Configuration options选项卡还允许您为特定工作流程中位于工作流程顶层(即不在组件或元节点内部)的所有Configuration节点设置值。此功能适用于KNIME Analytics Platform节点存储库的“工作流抽象”→“配置”类别中不包含传入连接(包括流变量)的所有节点。
# 通过KNIME工作流程访问本地文件系统
越来越多的KNIME节点(见下文)正在修订中,以使用新的共享框架进行文件访问。在接下来的发行版中将会有更多的节点,因此最终所有KNIME节点的文件访问都将使用共享框架。
在KNIME Server上执行时,首选项控制这些节点是否可以访问KNIME Server Executor的本地文件系统。在此版本中,默认情况下不允许本地文件系统访问(以前是允许的)。
要允许本地文件系统访问(不建议),可以将以下行添加到KNIME Server执行程序使用的自定义配置文件中:
/instance/org.knime.filehandling.core/allow_local_fs_access_on_server=true
此首选项当前会影响以下KNIME节点:Excel Reader(XLS),Excel Writer(XLS),Excel Sheet Appender(XLS),Line Reader。此外,这会影响新文件处理(实验室)类别中的所有节点。其他任何KNIME节点均不受此设置的影响。
# 服务器架构
KNIME Server是一个Java Enterprise Application,KNIME WebPortal是一个标准Java Web Application,都安装在Tomcat应用程序服务器上,蓝色图标位于下图的中间。用户可以登录到服务器,服务器将根据Tomcat提供的任何身份验证源进行身份验证。

KNIME Server的主要任务之一是管理和控制服务器的存储库。上载到服务器的工作流通过服务器应用程序并存储在存储库中,该存储库只是服务器文件系统上的一个文件夹(图中右侧的蓝色圆柱体)。一旦安装了客户端服务器扩展,就可以在KNIME Server中控制对存储的工作流的访问,并且可以从KNIME Explorer中操纵工作流的访问权限。
服务器上的工作流程执行是由KNIME执行器执行的。KNIME Executor是普通KNIME Analytics Platform应用程序的持久无头实例(上图中最左侧的元素)。
重要的是要注意,如果执行程序安装了必需的功能,并且与用于创建工作流程的KNIME Analytics Platform版本相同(或更新),则工作流程只能在服务器上成功加载和执行。
# 服务器配置文件和选项
# KNIME服务器配置文件
KNIME服务器由名为的特定于knime的配置文件配置 knime-server.config。该文件可以在中找到 /config/knime-server.config。可以在运行时更改此文件中定义的大多数参数,这些参数将尽快生效。默认值将用于空白或缺少的配置选项。
本节 KNIME服务器配置文件选项 (opens new window) 中包含的所有配置选项和解释的完整列表。有关适用于KNIME WebPortal的所有配置选项和说明的列表,请参阅 《 KNIME WebPortal管理指南》的 配置文件选项部分 (opens new window)。
# KNIME服务器配置文件选项
在下面,您将找到一个表格,其中包含所有受支持的配置选项(按字母顺序)。其中一些将在后面的部分中更详细地描述。可以在文件中设置选项 /config/knime-server.config。
对于Windows用户:对于服务器配置文件中的路径,请使用正斜杠(“ /”)或双反斜杠(“ \”)。单个反斜杠用于转义字符。
该表的以下批注提供了一些其他信息,这些信息涉及受影响的Executor类型以及更改是在运行时生效还是需要重新启动服务器。
| [ST] | 更改在重启KNIME Server后生效 |
|---|---|
| [RT] | 更改可以在运行时生效 |
| [回覆] | 更改仅影响RMI执行者 |
| [DE] | 更改仅影响KNIME执行器(请参阅此处 (opens new window)) |
Some options can be set as property in the knime-server.config file as well as by defining an environment variable (Env). The environment variable changes will only take effect after a restart of KNIME Server. If the environment variable for an option is set, the property in the configuration file will be ignored.
com.knime.server.admin_email=,,… [RT]A comma separated list of email addresses that will get notified when there is a problem with the server, e.g. the license is about to expire or the maximum number of users has been reached. |
|---|
com.knime.server.canonical-address= [RT]The communication between Executor and server is performed through the server’s REST interface. In case auto-detection of the server’s address doesn’t work correctly, you have to specify the canonical address here, e.g. http://knime-server:8080/. This option is not required if server and Executor are running on the same computer. See also section enabling workflow execution (opens new window) below for more details. Env: KNIME_SERVER_CANONICAL_ADDRESS= |
com.knime.server.config.watch= [ST]If set to true changes to the configuration file are applied immediately without a server restart. Default is false, i.e. all changes will require a server restart. |
com.knime.server.csp-report-only= [RT]Tells the browser to still serve content that violates the Content-Security-Policy and instead display a warning, by setting the Content-Security-Policy-Report-Only header rather than the Content-Security-Policy header (defaults to false). For more information about Content-Security-Policy-Report-Only, please refer to this resource (opens new window). |
com.knime.server.default_mount_id= [RT]Specifies the name of the default mount ID. This is fetched, when clients set up their mount point to the server. Defaults to the server’s hostname. Env: KNIME_SERVER_DEFAULT_MOUNT_ID= |
com.knime.enterprise.executor.embedded-broker= [ST]Enables the use of the embedded message queue (Apache Qpid) instead of a separate RabbitMQ installation. This allows you to run distributed KNIME Executors on the same system as the KNIME Server. By default this is enabled. |
com.knime.enterprise.executor.embedded-broker.port= [ST]Allows to configure the port for the embedded message queue (see option above). The default is 5672 and you should only change it if the port is already in use by another service. You also need to adjust the message broker address in the Executor’s knime.ini in this case. |
com.knime.enterprise.executor.msgq=amqp://:@/ [DE][ST]URL to the RabbitMQ virtual host. In case RabbitMQ High Available Queues (opens new window) are used, simply add additional : separated by commas to the initial amqp address: com.knime.enterprise.executor.msgq=amqp://:@rabbitmq-host/knime-server,amqp://:,amqp://: Note, this is supported with KNIME Server 4.11.3 onward. Env: KNIME_EXECUTOR_MSGQ=amqp://:@/ |
com.knime.enterprise.executor.msgq.connection_retries= [DE][ST]Defines the maximum number of connection retries for the message queue, that should be performed during server startup. The delay between retries is 10 seconds. The default is 9, `` has to be an integer value greater or equal to 1. For value less than 0 the number of retries is infinite. Env: KNIME_MSGQ_CONNECTION_RETRIES= |
com.knime.enterprise.executor.msgq.names=,,… [DE][ST]Defines the names of Executor Groups. The number of names must match the number of rules defined with com.knime.enterprise.executor.msgq.rules. See executor groups (opens new window) for more information. |
com.knime.enterprise.executor.msgq.rules=,,… [DE][ST]Defines the exclusivity rules of the Executor Groups. The number of rules must match the number of rules defined with com.knime.enterprise.executor.msgq.names. See executor groups (opens new window) for more information. |
com.knime.server.executor.blacklisted_nodes=,,… [RT]Specifies nodes that are blacklisted by the server, i.e. which aren’t allowed to be executed. For blacklisting a node you have to provide its factory name. Wildcards (*) are supported. For more information see here (opens new window). |
com.knime.server.executor.knime_exe= [RE][RT]Specifies the KNIME executable that is used to execute flows on the server. Default is none (no execution available on the server). This option is not used when using the default queue-based execution mode. |
com.knime.server.executor.prestart= [RE][ST]Specifies whether an Executor should be started during server startup or if it should be started on-demand when the first workflow is being executed. Default is to prestart the Executor. |
com.knime.server.executor.reject_future_workflows= [RT]Specifies whether the Executor should reject loading workflows that have been create with future versions. For new installations the value is set to true. If no value is specified the Executor will always try to load and execute any workflow by default. |
com.knime.server.executor.start_port= [RE][ST]Specifies the start port that the server uses to communicate with the KNIME Executor. Default is 60100. With multiple Executors and/or automatic Executor renewal multiple consecutive ports are used. |
com.knime.server.executor.update_metanodelinks_on_load= [RT]Specifies whether component links in workflows should be updated right after the workflow has been loaded in the KNIME Executor. Default is not to update component links. |
com.knime.server.job.async_load_reconnect_timeout= [DE][RT]Specifies the default connection timeout of asynchronously loaded jobs in case of a server restart. If a server restart occurs the server tries to reconnect to jobs that have been loaded asynchronously, as they might be still in the message queue or discarded due to an error. For this the maximum of the remaining load timeout or the async_load_reconnect_timeout is used to wait for status updates. If the time elapses without a status update loading will be canceled and the job state will be set to LOAD_ERROR. |
com.knime.server.job.default_cpu_requirement= [RT]Specifies the default CPU requirement in number of cores of jobs without a specific requirement set. See CPU and RAM requirements (opens new window) for more information. The default is 0. |
com.knime.server.job.default_load_timeout= [RT]Specifies how long to wait for a job to get loaded by an Executor. If the job does not get loaded within the timeout, the operation is canceled. The default is 1m. This timeout is only applied if no explicit timeout has been passed with the call. |
com.knime.server.job.default_ram_requirement= [RT]Specifies the default RAM requirement of jobs without a specific requirement set. See CPU and RAM requirements (opens new window) for more information. In case no unit is provided it is automatically assumed to be provided in megabytes. The default is 0MB. |
com.knime.server.job.default_report_timeout= [RT]Specifies how long to wait for a report to be created by an Executor. If the report is not created within the timeout, the operation is canceled. The default is 1m. This timeout is only applied if no explicit timeout has been passed with the call. |
com.knime.server.job.default_swap_timeout= [RT]Specifies how long to wait for a job to be swapped to disk. If the job is not swapped within the timeout, the operation is canceled. The default is 1m. This timeout is only applied if no explicit timeout has been passed with the call (e.g. during server shutdown). |
com.knime.server.job.discard_after_timeout= [RT]Specifies whether jobs that exceeded the maximum execution time should be canceled and discarded (true) or only canceled (false). May be used in conjunction with com.knime.server.job.max_execution_time option. The default (true) is to discard those jobs. |
com.knime.server.job.exclude_data_on_save= [DE][RT]Specifies whether node outputs of jobs that are saved as workflows shall be excluded. If this is set to true the resulting workflows will be reset, i.e. no output data are available at the nodes. The default value is false. |
com.knime.server.job.max_execution_time= [RT]Allows to set a maximum execution time for jobs. If a job is executing longer than this value it will be canceled and eventually discarded (see com.knime.server.job.discard_after_timeout option). The default is unlimited job execution time. Note that for this setting to work, com.knime.server.job.swap_check_interval needs to be set a value lower than com.knime.server.job.max_execution_time. |
com.knime.server.job.max_lifetime= [RT]Specifies the time of inactivity, before a job gets discarded (defaults to 7d), negative numbers disable forced auto-discard. |
com.knime.server.job.max_time_in_memory= [RT]Specifies the time of inactivity before a job gets swapped out from the Executor (defaults to 60m), negative numbers disable swapping. |
com.knime.server.job.status_update_interval= [RE][RT]Specifies the interval at which the running Executor instances are checked for unnoticed status changes and if they are still alive. Default is every 60s. |
com.knime.server.job.swap_check_interval= [RT]Specifies the interval at which the server will check for inactive jobs that can be swapped to disk. Default is every 1m. |
com.knime.server.login.allowed_groups =,,… [RT]Defines the groups that are allowed to log in to the server. Default value allows users from all groups. Env: KNIME_LOGIN_ALLOWED_GROUPS=,,… |
com.knime.server.login.consumer.allowed_accounts =,,… [RT]Defines account names that are allowed to log in to the server as consumer. Default value allows login as consumer for all users. Env: KNIME_CONSUMER_ALLOWED_ACCOUNTS=,,… |
com.knime.server.login.consumer.allowed_groups =,,… [RT]Defines the groups that are allowed to log in to the server as consumer. Default value allows login as consumer from all groups. Env: KNIME_CONSUMER_ALLOWED_GROUPS=,,… |
com.knime.server.login.jwt-lifetime= [RT]Defines the maximum lifetime of JSON Web Tokens issued by the server. The default value is 30d. A negative value allows unrestricted tokens (use this value with care because there is no way to revoke issued tokens). |
com.knime.server.login.user.allowed_accounts =,,… [RT]Defines account names that are allowed to log in to the server as user. Default value allows login as user for all users. |
com.knime.server.login.user.allowed_groups =,,… [RT]Defines the groups that are allowed to log in to the server as a user. Default value allows login as user from all groups. |
com.knime.server.report_formats= [RT]Defines the different formats available for report generation as a comma separated list of values. Possible values are html, pdf, doc, docx, xls, xlsx, ppt, pptx, ps, odp, odt and ods. If this value is empty or not set the default list of formats is html, pdf, docx, xlsx and pptx. |
com.knime.server.repository.update_recommendations_at= [RT]Defines a time during the day (in ISO format, i.e. 24h notation, e.g. 21:15) at which the node recommendations for the workflow coach are updated based on the current workflow repository contents. Default is undefined which means that no node recommendations will be computed and provided by the server. |
com.knime.server.server_admin_groups=,,… [RT]Specifies the admin group(s). Users belonging to at least one of these groups are considered KNIME Server admins (not Tomcat server admins). Default is no admin groups. Env: KNIME_SERVER_ADMIN_GROUPS=,,… |
com.knime.server.server_admin_users=,,… [RT]Specifies the user(s) that are KNIME Server admins (not Tomcat admins). Default is no users. |
com.knime.server.user_directories.directory_location= [ST]Specifies the base directory in which user directories shall be created on first login. All non existing directories of `` will be created and their owner set to the defined owner (com.knime.server.user_directories.parent_directory_owner). The permissions of the created directories are: owner: rwx, world: r--. If left empty no user directories will be created and all com.knime.server.user_directories options will be ignored. Note that only logins via the Analytics Platform will cause a user directory to be created. |
com.knime.server.user_directories.parent_directory_owner= [ST]Specifies the owner of the created directories of com.knime.server.user_directories.directory_location. If left empty the default value knimeadmin will be used. |
com.knime.server.user_directories.owner_permissions= [ST]Specifies the permissions of the owners (users themselves) for their created user directories. The defined permissions have to be in a block of 3 characters (r,w,x,-), e.g. rwx or r-x. If left empty the default value rwx is used. |
com.knime.server.user_directories.inherit_permissions= [ST]Specifies if the permissions of the created user directories shall be inherited from their parent directory. If left empty the default value false is used. |
com.knime.server.user_directories.groups=:,:,… [ST]Specifies the permissions of groups for the created user directories. The defined permissions have to be in a block of 3 characters (r,w,x,-), e.g. rwx or r-x. If left empty no group permissions are set. |
com.knime.server.user_directories.users=:,:,… [ST]Specifies the permissions of users for the created user directories. The defined permissions have to be in a block of 3 characters (r,w,x,-), e.g. rwx or r-x. If left empty no user permissions are set. |
com.knime.server.user_directories.world_permissions= [ST]Specifies the permissions of others for the created user directories. The defined permissions have to be in a block of 3 characters (r,w,x,-), e.g. rwx or r-x. If left empty the default value r-- is used. |
com.knime.server.action.upload.force_reset= [RT]Specfifies if all workflows shall be reset before being uploaded. This only works for workflows that are uploaded in the KNIME Analytics Platform 4.2 or higher. If left empty the default value false is used. The user can only change the reset behavior manually if /instance/org.knime.workbench.explorer.view/action.upload.enable_reset_checkbox is set to true, otherwise the behavior cannot be changed by the user. |
com.knime.server.action.upload.enable_reset_checkbox= [RT]If set to true together with com.knime.server.action.upload.force_reset the user has the option to change the reset behavior in the Deploy to Server dialog. This only works for workflows that are uploaded in the KNIME Analytics Platform 4.2 or higher. If left empty the default value false is used. |
com.knime.server.action.snapshot.force_creation= [RT]Specifies if a snapshot shall always be created when overwriting a workflow or file. This only works when overwriting workflows or files in the KNIME Analytics Platform 4.2 or higher. If left empty the default value false is used. |
In KNIME Analytics Platform, these options are supported by KNIME Server: add them to the knime.ini file, after the -vmargs line, each in a separate line.
-Dcom.knime.server.server_address=Sets the `` as the default Workflow Server in the client view.
# Default mount ID
KNIME supports mountpoint relative URLs using the knime protocol (see the KNIME Explorer User Guide (opens new window) for more details). Using this feature with KNIME Server requires both the workflow author and their collaborator to use the shared Mount IDs. With this in mind, you can now set a common name (Mount ID) for the server to all users.
The default name for your server can be specified in the configuration file:
com.knime.server.default_mount_id=<server name>
Please note that a valid Mount ID contains only characters a-Z, A-Z, '.' or '-'. It must start with a character and not end with a dot nor hyphen. Additionally, Mount IDs starting with knime. are reserved for internal use. | |
|---|---|
# Blacklisting nodes
You might want to prevent the usage of certain nodes on the Executor of KNIME Server. While you can decide, which extensions you install for the Executor there might be nodes in the basic installation of KNIME Analytics Platform or in a required extension that shouldn’t be used.
The configuration option
com.knime.server.executor.blacklisted_nodes=<node>,<node>,...
allows you to define a list of nodes that should be blocked by the Executor. This list also supports wildcards (*). If a workflow contains a blacklisted node the Executor will throw an error and abort loading the workflow.
To blacklist a node you have to provide the full name of the node factory. The easiest way to determine the factory names of the nodes you want to block is to create a workflow with all nodes that should be blacklisted. After saving the workflow you are able to access the settings.xml of each node under ///settings.xml. The factory name can be found in the entry with key "factory".
The following shows an example on how to block the Java Snippet nodes. The factory information for the Java Snippet node is
<entry key="factory" type="xstring" value="org.knime.base.node.jsnippet.JavaSnippetNodeFactory"/>
To block the Java Snippet node we simply provide the value (without the quotes)
com.knime.server.executor.blacklisted_nodes=org.knime.base.node.jsnippet.JavaSnippetNodeFactory
The factory names for Java Snippet (simple), Java Snippet Row Splitter, and Java Snippet Row Filter are
org.knime.ext.sun.nodes.script.JavaScriptingNodeFactory
org.knime.ext.sun.nodes.script.node.rowsplitter.JavaRowSplitterNodeFactory
org.knime.ext.sun.nodes.script.node.rowfilter.JavaRowFilterNodeFactory
Since they all share the same prefix, we append n factory name making use of wildcards:
com.knime.server.executor.blacklisted_nodes=org.knime.base.node.jsnippet.JavaSnippetNodeFactory,org.knime.ext.sun.nodes.script.*Java*
While users are still able to upload workflows containing these nodes, the Executor won’t load a workflow containing any of them.
# KNIME executor job handling
# Job swapping
Jobs that are inactive for a period of time may be swapped to disc and removed from the Executor to free memory or Executor instances. A job is inactive if it is either fully executed or waiting for user input (on the KNIME WebPortal). If needed, it will be retrieved from disk automatically.
The configuration option
com.knime.server.job.max_time_in_memory=<duration with unit, e.g. 60m, 36h, or 2d>
controls the period of inactivity allowed before a job will be swapped to disk (default = 60m). If you specify a negative number this feature is disabled and inactive jobs stay in memory until they are discarded.
| There are certain flows that will not be restored in the exact same state that it was in, before it got swapped out. For example, if a flow gets swapped with a loop partially executed, this loop iteration will be reset and the loop execution is restarted. | |
|---|---|
# Job auto-discard
There is an additional threshold for inactivity of a job after which it may be discarded automatically. A discarded job due to inactivity cannot be recovered. The time threshold for a job to be automatically discarded is controlled by setting
com.knime.server.job.max_lifetime=<duration with unit, e.g. 60m, 36h, or 2d>
The default value (if the option is not set) is 7d.
# Managing User and Consumer Access
It is possible to restrict which groups (or which individual users) are eligible to log in as either users or consumers. In this context, a user is someone who logs in from a KNIME Analytics Platform client to e.g. upload workflows, set schedules, or adjust permissions. On the other hand, a consumer is someone who can only execute workflows from either the KNIME WebPortal or via the KNIME Server REST API.
In order to control who is allowed to log in as either user or consumer, the following settings need to be adjusted in the knime-server.config:
com.knime.server.login.allowed_groups: This setting has to include all groups that should be allowed to login to KNIME Server, regardless of whether they are users or consumers.
com.knime.server.login.consumer.allowed_groups: List of groups that should be allowed to use the WebPortal or REST API to execute workflows.
com.knime.server.login.user.allowed_groups: List of groups that should be allowed to connect to KNIME Server from a KNIME Analytics Platform client.
# Usage Example
com.knime.server.login.allowed_groups`=`marketing,research,anaylsts
com.knime.server.login.consumer.allowed_groups`=`marketing,research,anaylsts
com.knime.server.login.user.allowed_groups`=`research
In the above example, we first restrict general access to KNIME Server to individuals in the groups marketing, research, and analysts. All individuals who are not in any of these groups won’t be able to access KNIME Server at all. Next, we allow all three groups to login as consumers via WebPortal or REST API. Finally, we define that only individuals in the group research should be able to log in as users from a KNIME Analytics Platform client.
| By default, these settings are left empty, meaning that as long as users are generally able to login to your KNIME Server (e.g. because they are in the allowed AD groups within your organization), they can log in as either users or consumers. Since the number of available user licenses is typically lower than the number of consumers, it is recommended to restrict user access following the above example. | |
|---|---|
# Executor Preferences
If the KNIME Executor requires certain preferences (e.g. database drivers or path to Python environment), you need to provide a preference files that the Executor(s) can retrieve from the application server.
To get a template of the preferences:
- Start KNIME (with an arbitrary workspace).
- Set all preferences via "File" → "Preferences") and export the preferences via "File" → "Export Preferences". This step can also be performed on a client computer but make sure that any paths you set in the preferences are also valid on the server.
Open the exported preferences and insert the relevant lines into /config/client-profiles/executor.epf
Note: Make sure to specify the paths of all database drivers in the new preference page, in order to be able to execute workflows with database nodes. The page is available in the KNIME → Database Drivers category of the preferences.
| It is recommended to only copy over the settings you will actually use on the Executor, like database drivers or Python preferences. The full preferences export is likely to contain e.g. host-specific paths that are not valid on the target system. | |
|---|---|
We have bundled a file called executor.epf into the /config/client-profiles/executor folder. In order for those preferences to be used, you must edit the knime.ini file of the executor and insert
-profileLocation
http://127.0.0.1:8080/<WebPortal Context ROOT, most likely "knime">/rest/v4/profiles/contents
-profileList
executor
before the line containing -vmargs. This only has to be done in case no Executor has been provided during the installation of KNIME Server, otherwise it is set automatically.
# Adding Executor preferences for headless Executors
In order to be able to execute workflows that contain database nodes that use custom or proprietary JDBC driver files on KNIME Server, the executor.epf file must contain the path to the JDBC jar file, or the folder containing the JDBC driver. This may be specified in the KNIME Analytics Platform (Executor) GUI and the executor.epf file exported as described in the above section. This is the recommended route for systems that have graphical access to the KNIME Analytics Platform (Executor).
Some systems do not have graphical access to the KNIME Analytics Platform (Executor) GUI. In that case the executor.epf can be manually created, or created on an external machine and copied into location on the server. The relevant lines that must be contained in the executor.epf file are:
file_export_version=3.0
\!/=
/instance/org.knime.workbench.core/database_drivers=/path/to/driver.jar;/path/to/driver-folder
/instance/org.knime.workbench.core/database_timeout=60
Note that driver.jar may also reference a folder in some cases (e.g. MS SQL Server and Simba Hive drivers).
| If you are using distributed KNIME Executors, please see the Server-managed Customization Profiles (opens new window) section of the KNIME Database Extension Guide (opens new window) for how to distribute JDBC drivers. | |
|---|---|
# knime.ini file
You might want to tweak certain settings of this KNIME instance, e.g. the amount of available memory or set system properties that are required by some extensions. This can be changed directly in the knime.ini in the KNIME Executor installation folder.
KNIME Server will read the knime.ini file next to the KNIME executable and create a custom ini file for every Executor that is started. However, if you use a shell script that prepares an environment the server may not be able to find the ini file if this start script is in a different folder. In this case the knime.ini file must be copied to /config/knime.ini. If this file exists, the server will read it instead of searching for a knime.ini next to the executable or start script.
# Log files
There are several log files that could be inspected in case of unexpected behavior:
# Tomcat server log
Location: /logs/catalina.yyyy-mm-dd.log
This file contains all general Tomcat server messages, such as startup and shutdown. If Tomcat does not start or the KNIME Server application cannot be deployed, you should first look into this file.
Location: /logs/localhost.yyyy-mm-dd.log
This file contains all messages related to the KNIME Server operation. It does not include messages from the KNIME Executor!
For new installations these files are kept for 90 days before being removed. The default behaviour can be changed by editing the /conf/logging.properties file and amending any entries with:
1catalina.org.apache.juli.FileHandler.maxDays = 90
# KNIME executor log
Location: /.metadata/knime/knime.log
The executor-workspace is usually in the home directory of the operating system user that runs the executor process and is called knime-workspace. If you provided a custom workspace using the -data argument when starting the executor you can find it there.
If you are still using deprecated RMI executors, the executor-workspace is /runtime/runtime_knime-rmi_.
This file contains messages from the KNIME Executor that is used to execute workflows on the server (for manually triggered execution, scheduled jobs, and also for generated reports, if KNIME Report Server is installed)
The executor’s log file rotates every 10MB by default. If you want to increase the log file size (to 100MB for example), you have to append the following line at the end of the executor’s knime.ini:
-Dknime.logfile.maxsize=100m
Also useful in some cases is the Eclipse log file /.metadata/.log
# KNIME Analytics Platform (client) log
Location: /.metadata/knime/knime.log
This file contains messages of the client KNIME application. Messages occurring during server communications are logged there. The Eclipse log of this application is in /.metadata/.log
# Email notification
KNIME Server allows users to be notified by email when a workflow finishes executing. The emails are sent from a single email address which can be configured as part of the web application’s mail configuration. If you don’t want to enable the email notification feature, no email account is required. You can always change the configuration and enter the account details later.
# Setting up the server’s email resource
The email configuration is defined in the web application context configuration file which is /conf/Catalina/localhost/knime.xml (or com.knime.enterprise.server.xml or similar). The installer has already created this file. In order to change the email configuration, you have to modify or add attributes of/to the `` element. All configuration settings must be added as attributes to this element. The table below shows the list of supported parameters (see also the JavaMail API documentation (opens new window)). Note that the mail resource’s name must be mail/knime and cannot be changed.
| Name | Value |
|---|---|
mail.from | Address from which all mails are sent |
mail.smtp.host | SMTP server, required |
mail.smtp.port | SMTP port, default 25 |
mail.smtp.auth | Set to true if the mail server requires authentication; optional |
mail.smtp.user | Username for SMTP authentication; optional |
password | Password for SMTP authentication; optional |
mail.smtp.starttls.enable | If true, enables the use of the STARTTLS command (if supported by the server) to switch the connection to a TLS-protected connection before issuing any login commands. Defaults to false. |
mail.smtp.ssl.enable | If set to true, use SSL to connect and use the SSL port by default. Defaults to false. |
If you do not intend to use the email notification service (available in the KNIME WebPortal (opens new window) for finished workflow jobs), you can skip this step.
Note that the mail configuration file contains the password in plain text. Therefore, you should make sure that the file has restrictive permissions.
# User authentication
As described briefly in the Server architecture (opens new window) section it is possible to use any of the authentication methods available to Tomcat in order to manage user authentication. By default the KNIME Server installer configures a database (H2) based authentication method. Using this method it is possible for admin users to add/remove users/groups via the AdminPortal using a web-browser. Other users may change their password using this technique.
For enterprise applications, use of LDAP authentication is recommended, and user/group management is handled in Active Directory/LDAP itself.
In all cases the relevant configuration information is contained in the
`<Realm className="org.apache.catalina.realm.LockOutRealm">`
tag in /conf/server.xml.
The default configuration uses a CombinedRealm which allows multiple authentication methods to be used together. Examples for each of database, file and LDAP authentication are contained within the default installation. Configuration of all three authentication methods are described briefly in the following sections. In all cases the Tomcat documentation (opens new window) should be considered the authoritative information source.
# LDAP authentication
LDAP authentication is the recommended authentication in any case where an LDAP server is available. If you are familiar with your LDAP configuration you can add the details during installation time, or edit the server.xml file post installation. If you are unfamiliar with your LDAP settings, you may need to contact your LDAP administrator, or use the configuration details for any other Tomcat based system in your organization. Please refer to the KNIME Server Advanced Setup Guide (opens new window) for details on setting up LDAP.
# Connecting to an SSL secured LDAP server
In case you are using encrypted LDAP authentication and your LDAP server is using a self-signed certificate, Tomcat will refuse it. In this case you need to add the LDAP server’s certificate to the global Java keystore, which is located in /lib/security/cacerts:
keytool -import -v -noprompt -trustcacerts -file \
<server certificate> -keystore <jre>/lib/security/cacerts \
-storepass changeit
Alternatively you can copy the cacerts file, add your server certificate, and add the following two system properties to /conf/catalina.properties:
javax.net.ssl.trustStrore=<copied keystore>
javax.net.ssl.keyStorePassword=changeit
# Single-sign-on with LDAP and Kerberos
It is possible to use Kerberos in combination with LDAP for Single-Sign-On for authentication with KNIME Server.
This is an advanced topic and is covered in the KNIME Server Advanced Setup Guide (opens new window).
# Token-based authentication
KNIME Server also allows authentication by JWT (JSON Web Tokens) that have previously been issued by the server. The REST endpoint /rest/auth/jwt can be used to acquire such a JWT for the currently logged in user. Subsequent requests need to carry the token in the Authorization header as follows:
Authorization: Bearer xxx.yyy.zzz
where xxx.yyy.zzz is the JWT. Token-based authentication is enabled by default and cannot be disabled. However, you can restrict the maximum lifetime of JWTs issued by the server via the server configuration option com.knime.server.login.jwt-lifetime, see section KNIME Server configuration file options (opens new window).
The OpenAPI documentation for the REST API which can be found at: https:///knime/rest/doc/index.html#/Session should be considered the definitive documentation for this feature.
# Large number of users in a group
Since the JWT includes the group membership for the user, this can get very large in some cases. JWTs with more than 30 groups and that are larger than 2kB are now compressed. If they are still larger than 7kB a warning is logged with hints how to resolve potential problems.
One solution is to increase the maximum HTTP header size in Tomcat by adding the attribute maxHttpHeaderSize="32768" to all defined Connectors in the server.xml (the default is 8kB). In case Tomcat is running behind a proxy, the limit may need to be increased there, too. In case of Apache it’s the global setting LimitRequestFieldSize 32768.
# Database-based authentication
Database-based authentication is recommended to be used by small workgroups who do not have access to an LDAP system, or larger organisations in the process of trialing KNIME Server. If using the previously described H2 database it is possible to use the AdminPortal to manage users and groups. It is possible to use other SQL databases e.g. PostgreSQL to store user/group information, although in this case it is not possible to use the AdminPortal to manage users/groups, management must be done in the database directly.
For default installations this authentication method is enabled within the server.xml file. No configuration changes are required. In order to add/remove users, or create/remove groups the administration pages of the WebPortal can be used. The administration pages can be located by logging into the WebPortal as the admin user, see section Administration pages (opens new window) on the KNIME WebPortal Administration Guide for more details.
Batch insert/update of usernames and roles is possible using the admin functionality of the KNIME Server REST API. This is described in more detail in the section RESTful webservice interface (opens new window). A KNIME Workflow is available in the distributed KNIME Server installation package that can perform this functionality.
# File-based authentication
For KNIME Server versions 4.3 or older the default configuration used a file-based authentication which we describe for legacy purposes. It is now recommended to use either database-based or LDAP authentication. The advantages of each are described in the corresponding sections above and below.
The XML file /conf/tomcat-users.xml contains examples on how to define users and groups (roles). Edit this file and follow the descriptions. By default this user configuration file contains the passwords in plain text. Encrypted storage of passwords is described in the Tomcat documentation.
# Configuring a license server
Since version 4.3 KNIME Server can distribute licenses for extensions to the KNIME Analytics Platform (e.g. Personal Productivity, TeamSpace, or Big Data Connectors) to clients. In order to use the license server functionality, you require a master license. Every KNIME Server Large automatically comes with TeamSpace client licenses for the same number of users as the server itself.
The master license file(s) should be copied into the licenses folder of the server repository (next to the server’s license). The server will automatically pick up the license and offer them to clients. For configuring the client, see the section about "Retrieving client licenses" in the KNIME Explorer User Guide (opens new window).
Client licenses distributed by the server are stored locally on the client and are tied to the user’s operating system name (not the server login!) and its KNIME Analytics Platform installation and/or the computer. They are valid for five days by default which means that the respective extensions can be used for a limited time even if the user doesn’t have access to the license server.
If the user limit for a license has been reached, no further licenses will be issued to clients until at least one of the issued licenses expires. The administrator will also get a notification email in this case (if their email notification is configured, see previous section Email notification (opens new window)).
# License renewal
If the server is not behaving as expected due to license issues, please contact KNIME by sending an email to support@knime.com or to your dedicated KNIME support specialist.
If the license file is missing or is invalid a message is logged to the server’s log file during server start up. KNIME clients are not able to connect to the server without a valid server license. Login fails with a message "No license for server found".
If the KNIME Server license has expired connecting clients fail with the message "License for enterprise server has expired on …". Please contact KNIME to renew your license.
If more users than are licensed attempt to login to the WebPortal, some users will see the message: "Maximum number of WebPortal users exceeded. The current server license allow at most
After you receive a new license file, remove the old expired license from the /licenses folder. In case there are multiple license files in this folder, find the one containing a line with
"name" = "KNIME Server"
and the "expiration date" set to a date in the past. The license file is a plain text file and can be read in any text editor.
Store the new license file in the license folder with the same owner and the same permissions as the old file.
The new license is applied immediately; a server restart is not necessary.
# Backup and recovery
The following files and/or directories need to be backed up:
- The full server repository folder, except the
tempfolder - The full Tomcat folder
- In case you installed your own molecule sketcher for the KNIME WebPortal (see above), also backup this folder.
A backup can be performed while the server is running but it’s not guaranteed that a consistent state will be copied as jobs and the workflow repository may change while you are copying files.
In order to restore a backup copy the files and directories back to their original places and restart the server. You may also restore to different location but make sure to adjust the paths in the start script, the repository location in the context configuration file, and paths in the server configuration.
# KNIME Executor installation
Install the open-source KNIME Analytics Platform 4.2 on the server. Install all additional extensions users may need to run their workflows on the server. Make sure to include the "KNIME Report Designer" extension. Also install all extensions listed in the "KNIME Server Executor" category, either from the default online update site that or from the update site archive that you can get from the download area there. Note that the versions of the KNIME Server Executor extensions must match the server’s version (e.g. "4.11")! Therefore, please check that you are installing from these extensions from correct update sites if you are not using the latest released versions of both the server and Executor.
| The easiest way to achieve this is to download the KNIME Executor full build from here (opens new window) and extract it. It includes all extensions required for running as an Executor for a KNIME Server. | |
|---|---|
Make sure that users other than the installation owner either have no write permissions to the installation folder at all or that they have full write permission to at least the "configuration" folder. Otherwise you may run into strange startup issues. We strongly recommend revoking all write permissions from everybody but the installation owner.
If the server does not have internet access, you can download zipped update sites (from the commercial downloads page) which contain the extensions that you want to install. Go to the KNIME preferences at File → Preferences → Install/Update → Available Software Sites and add the zip files as "Archives". In addition you need to disable all online update sites on the same page, otherwise the installation will fail. Now you can install the required extensions via File → Install KNIME Extensions….
# Installing additional extensions
The easiest way to install additional extensions into the Executor (e.g. Community Extensions or commercial 3rd party extensions) is to start the Executor in GUI mode and install the extensions as usual. In case you don’t have graphical access to the server you can also install additional extensions without a GUI. The standard knime executable can be started with a different application that allows changing the installation itself:
./knime -application org.eclipse.equinox.p2.director -nosplash
-consolelog -r _<list-of-update-sites>_ -i _<list-of-features>_ -d _<knime-installation-folder>_
Adjust the following parameters to your needs:
``: a comma-separated list of remote or local update sites to use. ZIP files require a special syntax (note the single quotes around the argument). Example:
-r 'http://update.knime.org/analytics-platform/4.2,jar:file:/tmp/org.knime.update.analytics-platform_4.2.0.zip!/'Some extensions, particularly from community update sites, have dependencies to other update sites. In those cases, it it necessary to list all relevant update sites in the installation command. - Adding the following four update sites should cover the vast majority of cases:
- http://update.knime.com/analytics-platform/4.2
- http://update.knime.com/community-contributions/4.2
- http://update.knime.com/community-contributions/trusted/4.2
- http://update.knime.com/partner/4.2
- Adding the following four update sites should cover the vast majority of cases:
``: a comma-separated list (spaces after commas are not supported) of features/extensions that should be installed. You can get the necessary identifiers by looking at Help → About KNIME → Installation Details → Installed Software in a KNIME instance that has the desired features installed. Take the identifiers from the "Id" column and make sure you don’t omit the
.feature.groupat the end (see also screenshot on the next page). Example:-i org.knime.product.desktop,org.knime.features.r.feature.groupYou can get a list of all installed features with:
./knime -application org.eclipse.equinox.p2.director -nosplash \ -consolelog -lir -d _<knime-installation-folder_``: the folder into which KNIME Analytics Platform should be installed (or where it is already installed). Example:
-d /opt/knime/knime_4.2
# Updating the Executor
Update of an existing installation can be performed by using the update-executor.sh script in the root of the installation. You only have to provide a list of update sites that contain the new versions of the installed extensions and all installed extension will be updated (given that an update is available):
./update-executor.sh http://update.knime.com/analytics-platform/4.2
If you want to selectively update only certain extensions, you have to build the update command yourself. An update is performed by uninstalling (-u) and installing (-i) an extension at the same time:
./knime -application org.eclipse.equinox.p2.director -nosplash -consolelog -r <list-of-update-sites> -i
<list-of-features> -u <list-of-features> -d <knime-installation-folder>
例如,要更新大数据扩展,请运行以下命令:
./knime -application org.eclipse.equinox.p2.director -nosplash \
-consolelog -r http://update.knime.com/analytics-platform/4.2 -i
org.knime.features.bigdata.connectors.feature.group,org.knime.features.bigdata.spark.feature.group
-u org.knime.features.bigdata.feature.group,org.knime.features.bigdata.spark.feature.group -d $ PWD
# 启用工作流程执行
安装了带有所有必需扩展程序的KNIME Executor后,您必须告诉服务器在哪里可以找到Executor。将com.knime.server.executor.knime_exe服务器配置中的值设置 为knime 可执行文件。该路径可以是绝对路径,也可以是相对于服务器配置文件夹(/config)的路径。可以在服务器运行时更改执行器的路径,该路径将在启动新执行器时使用(例如,在加载第一个工作流时)。
对于Windows用户:对于服务器配置文件中的路径,请使用正斜杠(“ /”)或双反斜杠(“ \”)。单个反斜杠用于转义字符。
有时,在执行器中运行的工作流程作业想要访问服务器上的文件,例如,通过相对于工作流程的URL或使用服务器的安装点ID的URL。由于执行器无法使用用户密码对服务器进行身份验证(因为服务器和执行器通常都不知道),因此在启动(或计划)工作流程时,服务器会生成令牌。该令牌表示用户,包括其创建时的组成员身份 。如果在工作流作业仍在运行或有进一步的计划执行期间更改组成员身份,这些更改将不会反映在工作流执行中。同样,如果已经完全撤消了用户的访问权限,则现有(计划的)作业仍可以访问服务器存储库。
如果Executor在与服务器不同的计算机上运行,请注意以下几点:服务器和Executor之间的通信部分通过REST接口执行,例如,当工作流程从服务器存储库请求文件时。因此,执行程序必须知道服务器的地址。服务器尝试自动检测其地址,并将其发送给执行程序。但是,如果服务器在代理服务器(例如Apache)后面运行,或具有与内部服务器不同的外部IP地址,则自动检测将提供错误的地址,执行器将无法访问服务器。在这种情况下,您必须将配置选项 com.knime.server.canonical-address设置为服务器的规范地址,例如 http://knime-server.behind.proxy/(您无需提供服务器应用程序的路径)。执行者必须可以使用该地址。
# KNIME Executors
# Distributed KNIME Executors: Introduction
As part of a highly available architecture, KNIME Server 4.11 allows you to distribute execution of workflows over several Executors that can sit on separate hardware resources. This allows KNIME Server to scale workflow execution with increasing load because it is no longer bound to a single computer.
If you’re planning to use the distributed KNIME Executors in production environments please get in touch with us directly for more information.
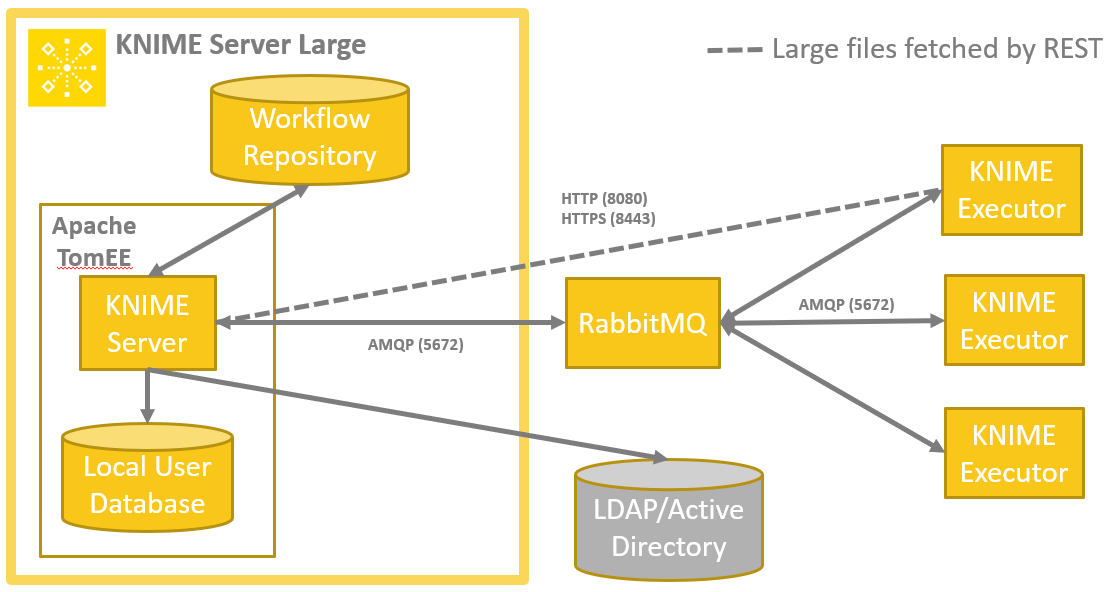
Installation, configuration, and operation is very similar to the single Executor setup. The server communicates with the Executors via a message queueing system (and HTTP(S)). We use RabbitMQ for this purpose, and it’s recommended, although not required, to install that on a separate machine as part of a highly available architecture.
# Distributed KNIME Executors: Installation instructions
Enabling KNIME Executors consists of the following steps:
- In case you haven’t installed KNIME Server already, please follow the KNIME Server Installation Guide (opens new window).
- Shut down the server if it has been started by the installer.
- Install RabbitMQ following the instructions below.
- Adjust configuration files for the server and Executor following the instructions below.
- Start the server and one or more Executors.
# Installing RabbitMQ
The server talks to the Executors via a message queueing system called RabbitMQ (opens new window). This is a standalone service that needs to be installed in addition to KNIME Server and the executors. You can install it on the same computer as KNIME Server or on any other computer directly reachable by both KNIME Server and the Executors.
KNIME Server requires RabbitMQ 3.6+ which can be installed according to the Get Started documentation on their web page (opens new window).
Make sure RabbitMQ is running, then perform the following steps:
- Enable the RabbitMQ management plug-in by following the online documentation (opens new window)
- Log into the RabbitMQ Management which is available at
http://localhost:15672/(with user guest and password guest if this is a standard installation). The management console can only be accessed from the host on which RabbitMQ is installed. - Got to the Admin tab and add a new user, e.g. knime.
- Also in the Admin tab add a new virtual host (select the virtual hosts section on the right), e.g. using the hostname on which KNIME Server is running or simply knime-server.
- Click on the newly created virtual host, go to the Permissions section and set permission for the new knime user (all to ".*" which is the default).
# Connecting Server and KNIME Executors
KNIME Server and the KNIME Executors now need to be configured to connect to the message queue.
For KNIME Server you must specify the address of RabbitMQ instead of the path to the local Executor installation in the knime-server.config. I.e. comment out the com.knime.server.executor.knime_exe option (with a hash sign) and add the option com.knime.enterprise.executor.msgq. The latter takes a URL to the RabbitMQ virtual host: amqp://:@/, e.g.
com.knime.enterprise.executor.msgq=amqp://<username>:<password>@rabbitmq-host/knime-server
Note that any special characters in the password must be URL encoded.
The same URL must also be provided to the Executor as system property via the knime.ini:
-Dcom.knime.enterprise.executor.msgq=amqp://<username>:<password>@rabbitmq-host/knime-server
Alternatively you can provide the message queue address as an environment variable:
KNIME_EXECUTOR_MSGQ=amqp://<username>:<password>@rabbitmq-host/knime-server
In case RabbitMQ High Available Queues (opens new window) are used, simply add additional : separated by commas to the initial amqp address (this is supported with KNIME Server 4.11.3 onward): | |
|---|---|
-Dcom.knime.enterprise.executor.msgq=amqp://<username>:<password>@rabbitmq-host/knime-server,amqp://<rabbitmq-host2>:<port2>,amqp://<rabbitmq-host3>:<port3>
In order to use RabbitMQ, you need to explicitly deactivate the embedded Qpid message broker by setting com.knime.enterprise.executor.embedded-broker=false in knime-server.config. Qpid does not support more than one KNIME Executor, and it doesn’t support Executors running on separate hosts. | |
|---|---|
While commands between the server and KNIME Executors are exchanged via the message queue, actual data (e.g. workflows to be loaded) are exchanged via HTTP(S). Therefore, the KNIME Executors must know where to reach the server. The server tries to auto-detect its own address however in certain cases this address is not reachable by the KNIME Executors or — in case of https connections — the hostname doesn’t match the certificate’s hostname. In such cases you have to specify the correct public address in the knime-server.config with the option com.knime.server.canonical-address, e.g.
com.knime.server.canonical-address=https://knime-server:8443/
You don’t have to specify the context path as this is reliably auto-detected. Now you can start the server.
The KNIME Executors must be started manually, the server does not start them. In order to start an Executor (on any machine) launch the KNIME application (that has been created by the installer) with the following arguments:
./knime -nosplash -consolelog -application com.knime.enterprise.slave.KNIME_REMOTE_APPLICATION
You can also add these arguments at the top of the knime.ini if the installation is only used as an Executor. You can start as many KNIME Executors as you like and they can run on different hosts. They will all connect to RabbitMQ (you can see them in the RabbitMQ Management in the Connections tab).
在外壳中启动Executor时,可以使用非常简单的命令行界面来控制Executor。help在Executor>提示符下输入以获取可用命令的列表。
在Windows上,将为执行器进程打开一个单独的窗口。如果在启动过程中出现问题(例如,执行器无法从服务器获取核心令牌),则此窗口将立即关闭。在这种情况下,您可以添加-noexit到上面的命令中以使其保持打开状态,并查看日志输出或打开日志文件(默认情况下为打开),/knime-workspace/.metadata/knime/knime.log 除非您使用提供了不同的工作区位置-data。
您可能会发现执行者使用KNIME服务器提供的自定义配置文件会有所帮助。在这种情况下,请参阅“文档”部分中的“自定义” (opens new window)。例如,编辑执行器的启动命令将应用executor配置文件。
./knime -nosplash -consolelog -profileLocation http:// knime-server:8080 / knime / rest / v4 / profiles / contents -profileList
执行器com.knime.enterprise.slave.KNIME_REMOTE_APPLICATION
# 将KNIME执行器作为服务运行
也可以将KNIME Executors作为服务在系统启动期间自动启动(并在关闭期间停止)。当不在docker部署上运行时,这是推荐使用的方法。
# 带有systemd的Linux
仅在使用systemd的Linux发行版 (例如Ubuntu> = 16.04,RHEL 7.x及其衍生版本)上支持将KNIME Executors作为服务运行。以下步骤假定您已安装KNIME Executor,其中包含KNIME executor安装 (opens new window) 一节中介绍的KNIME Executor连接器扩展。
复制整个文件夹
<knime安装> / systemd /到文件系统的根目录。该文件夹包含knime-executor的systemd服务描述和允许配置服务的替代文件(例如,文件系统位置或应在其中运行Executor的用户ID)。
跑
systemctl守护程序重新加载跑
systemctl编辑knime-executor.service在将打开的编辑器中调整设置,然后保存更改。确保
User此文件中指定的内容在系统上存在。否则,除非您的systemd版本支持,否则启动将失败DynamicUser。在这种情况下,将创建一个临时用户帐户。通过启用服务
systemctl启用knime-executor.service
# 视窗
在Windows上,可以使用NSSM(非吸吮服务管理器)将KNIME Executors作为Windows服务运行。以下步骤假定您具有KNIME Analytics Platform安装,其中包含KNIME Server安装指南 (opens new window)中所述的 KNIME Executor连接器扩展 。
编辑
<knime安装> /install-executor-as-service.batand adjust the variables at the top of the file to your needs.
Run this batch file as administrator. This will install the service.
Open the Windows Services application, look for the KNIME Executor service in the list and start it.
If you want to remove the Executor service again, run the following as administrator:
<knime-installation>/remove-executor-as-service.bat
Note that if you move the KNIME Executor installation you first have to remove the service before moving the installation and then re-create it.
# Load throttling
If too many jobs are sent to KNIME Executors this may overload them and all jobs running on that Executor will suffer and potentially even fail if there aren’t sufficient resources available any more (most notably memory). Therefore an Executor can reject new jobs based on its current load. By default an Executor will not accept new jobs any more if its memory usage is above 90% (Java heap memory, averaged over 1-minute) or the average system load is above 90% (averaged over 1-minute). These settings can be changed by two system properties in the Executor’s knime.ini file:
Some options can be set as property in the knime.ini file as well as by defining an environment variable (Env). The environment variable changes will only take effect after a restart of the KNIME Executor. If the environment variable for an option is set, the property in the 'knime.ini' file will be ignored.
-Dcom.knime.enterprise.executor.heapUsagePercentLimit=The average Heap space usage of the executor JVM over one minute. Default 90 percent Env: KNIME_EXECUTOR_HEAP_USAGE_PERCENT_LIMIT= |
|---|
-Dcom.knime.enterprise.executor.cpuUsagePercentLimit=The average CPU usage of the executor JVM over one minute. Default 90 percent. Env: KNIME_EXECUTOR_CPU_USAGE_PERCENT_LIMIT= |
If only one KNIME Executor is available it will accept every job despite the defined Heap space and CPU limits. With KNIME Server 4.9.0 and later an option to change this behavior has been added. For more information see the Automated Scaling (opens new window) section.
# Resource throttling
In some cases you may wish to restrict the access to the total available CPU cores/threads on the machine. Examples of when this may be desired are: when additional KNIME Executor cores on the machine must be reserved for another task, or in a local docker setup where containers detect all cores available on a machine. Both of these setups are typically not recommended as it can be difficult to guarantee good resource sharing, generally it’s better to run workloads on individual machines or isolated pods using Kubernetes.
/instance/org.knime.workbench.core/knime.maxThreads=This setting must be added to the preferences.epf file used by the Executor, or alternatively to the preference profile for the Executor. The number of threads that KNIME Executor will use to process workflows. In normal operation you do not need to set this preference. The Executor will auto-detect the number of cores available on the system, and set knime.maxThreads=2*num_cores. Typically the JVM will identify hyper-threaded cores as a 'core'. By default the Executor will use two times the numbers of cores available to the JVM.
# Automated Scaling
Currently we allow automated scaling by monitoring Executor heap space and CPU usage. It is also possible to blend these metrics using custom logic to invent custom scaling metrics. In some cases it may also be desirable to allow jobs to stack up on the queue and use the 'queue depth' as a fourth metric type. In order to do so, it is necessary to edit the knime.ini of the Executors.
-Dcom.knime.enterprise.executor.allowNoExecutors=com.knime.server.job.default_load_timeout and the com.knime.explorer.job.load_timeout in the Analytics Platform to ensure sensible behaviour. The default is false, which emulates the behaviour before the setting was added.
When using an automatic scaling setup, jobs that are waiting for an Executor to start, might run into timeouts. The default wait time for a job to be loaded by an Executor can be increased by setting the com.knime.server.job.default_load_timeout option in the server configuration as described in section Server configuration files and options (opens new window).
When starting jobs interactively using the Analytics Platform, the connection might also time out. The timeout can be increased by adding the following option to the knime.ini file of the KNIME Analytics Platform.
-Dcom.knime.explorer.job.load_timeout=Specifies the timeout to wait for the job to be loaded. The default duration is 5m.
Generally, the timeout in the Analytics Platform should be higher than the timeout set in the KNIME server. This prevents the interactive session from running into read timeouts.
# 重新连接到消息队列
万一与消息队列的连接丢失(例如,通过重新启动RabbitMQ),则从KNIME Server 4.11开始,执行程序将尝试重新连接到消息队列。可以在执行knime.ini程序的文件中调整以下选项:
-Dcom.knime.enterprise.executor.connection_retries=指定应尝试重新连接到消息队列的重试次数。在每次尝试之间,执行程序等待10秒。默认值设置为,9即执行器尝试重新连接90秒钟。请注意,也可以通过环境变量设置此选项KNIME_EXECUTOR_CONNECTION_RETRIES,该变量优先于knime.ini文件中设置的系统属性。对于number of retries小于0的重试次数是无限的。
# 工作池
对于频繁执行的工作流程,现在(从KNIME Server 4.8.1开始)可以将来自该工作流程的一定数量的作业保留在内存中。这消除了首次使用该作业后在执行程序中加载工作流的开销。在作业加载时间比作业执行时间大的情况下,这应该特别有益。
# 启用工作池
为了启用作业池,必须在应合并的工作流上设置属性。可以在KNIME Explorer(从KNIME Server 4.9.0开始)中进行设置,方法是右键单击工作流程并选择'Properties ...'。将打开一个对话框,使用户可以查看和编辑工作流程的属性。
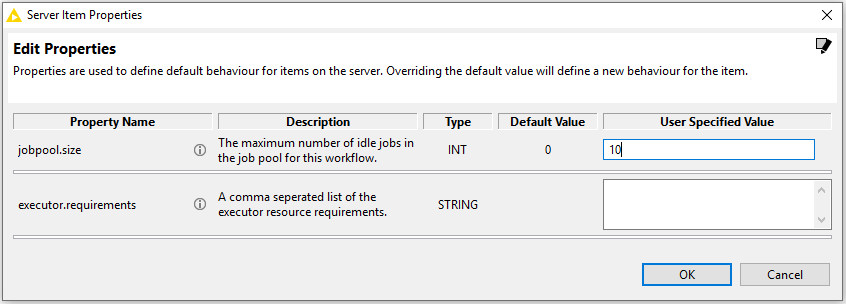
否则,也可以通过REST调用来设置工作流属性,例如,使用curl:
curl -X PUT -u <用户>:<密码> http:// <服务器地址> / knime / rest / v4 /存储库/ <工作流程>:properties?com.knime.enterprise.server.jobpool.size = <泳池面积>
这将为工作流工作流启用最多具有池大小作业的池。
仅在一次调用(即当前:execution资源)中进行加载,执行和丢弃的单次调用执行才有可能。客户端通过多个REST调用(加载,执行,重新执行,丢弃)执行的作业无法合并。
# 禁用工作池
可以通过在KNIME Explorer中或通过REST调用将作业池大小设置为0来禁用作业池:
curl -X PUT -u <用户>:<密码> http:// <服务器地址> / knime / rest / v4 /存储库/ <工作流程>:properties?com.knime.enterprise.server.jobpool.size = 0
# 使用工作池
为了利用池中的作业,必须调用特殊的REST资源来执行作业。不必呼唤,:execution您必须致电:job-pool。除此之外,这两个调用在语义和允许的参数方面是相同的。
执行合并的作业可能如下所示:
curl -u <用户>:<密码> http:// <服务器地址> / knime / rest / v4 /存储库/ <工作流>:作业池?p1 = v1&p2 = v2
This will call workflow passing v1 for input parameter p1 and v2 for input parameter p2. Calls using POST will work in a similar way using the :job-pool resource.
# Behaviour of job pools
Job pools exhibit a certain behaviour which is slightly different from executing a non-pooled job. Clients should be aware of those differences.
- If the pool is empty (either intially or if all pooled jobs are currently in use) the job will be loaded from the workflow and thus the call will take longer.
- A used job will be put back into the pool right after the result has been returned if the pool isn’t already full. Otherwise the job will be discarded.
- Pooled jobs are tied to the user that triggered initial loading of the job. A pooled job will never be shared among different users.
- If there is no job in the pool for the current user, the oldest job in the pool from a different user will be removed. This can lead to contention if there are more distinct users calling out to the pool than the pool size.
- Pooled jobs will be removed if they are unused for more than the configured job swap timeout (see the server configuration options (opens new window)).
- A pooled job without any input nodes will be reset before every invocation, even the first one! This is different from executing a non-pooled job but is required for consistent behaviour across multiple invocations. Otherwise the first and subsequent operations may behave differently if the workflow is saved with some executed nodes.
- In a pooled job with input nodes all of them will receive input values before execution: either the value that has been passed in the call, or if no explicit value has been provided its default value. This means that all input nodes will be reset prior to execution and not just the nodes explicitly set in the call. Again, this is different from executing a non-pooled job where only input nodes with explicitly provided values will be reset but required for consistency. Otherwise the results of a call may depend on the parameters passed in the previous call.
# Workflow Pinning
Workflow Pinning can be used to let workflows only be executed by a specified subset of the available KNIME Executors when distributed KNIME Executors (opens new window) are enabled.
For workflows that need certain system requirements (e.g. specific hardware, like GPUs, or system environments, like Linux) it’s now possible (starting with KNIME Server 4.9.0) to define such Executor requirements per workflow. Only KNIME Executors that fulfill the Executor requirements will accept and execute the workflow job. To achieve this behaviour, a property has to be set for the workflows. Additionally, the system admin of the KNIME Executors has to specify a property for each Executor seperately. The properties consist of values that define the Executor requirements, set for a workflow, and Executor resources, set for an Executor, respectively.
# Prerequisites for workflow pinning
In order to use workflow pinning, the KNIME Server Distributed Executors (opens new window) must be enabled and RabbitMQ (opens new window) must be installed. Otherwise, the set Executor requirements are ignored.
# Setting executor.requirements property for a workflow
Executor requirements for a workflow can be defined by setting a property on the workflow. The Executor requirements are a simple comma-seperated list of user-defined values. Setting workflow properties can be done in the KNIME Explorer by right-clicking on a workflow and selecting 'Properties…'. A dialog will open that lets the user view and edit the properties of a workflow.
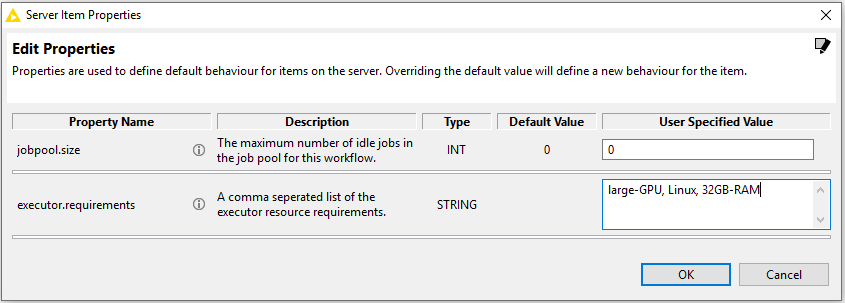
Alternatively, workflow properties can also be set via a REST call, e.g. using curl:
curl -X PUT -u <用户>:<密码> http:// <服务器地址> / knime / rest / v4 /存储库/ <工作流程>:properties?com.knime.enterprise.server.executor.requirements = <执行者要求>
这将为工作流工作流设置执行者要求执行者要求。
# 为执行者设置executor.resources属性
要定义执行者可以提供的资源,必须为执行者设置一个属性。这可以通过两种方式完成:
在执行器的系统上设置环境变量。变量的名称必须为“ KNIME_EXECUTOR_RESOURCES”,并且该值必须是用户定义值的逗号分隔列表。
KNIME_EXECUTOR_RESOURCES =值1,值2,值3在knime.ini文件中设置系统属性,该文件位于Executor的安装文件夹中。该文件包含执行器的配置设置,即Java虚拟机使用的选项。该属性的名称必须为“ com.knime.enterprise.executor.resources”,并且该值必须是用户定义值的逗号分隔列表。
-Dcom.knime.enterprise.executor.resources = value1,value2,value3
| 如果同时指定了环境变量和系统属性,则它们具有优先级。 | |
|---|---|
# 删除工作流程的executor.requirements属性
通过将属性设置为空字段可以删除执行器要求。可以在KNIME Explorer中或通过REST调用来完成:
curl -X PUT -u <用户>:<密码> http:// <服务器地址> / knime / rest / v4 /存储库/ <工作流程>:properties?com.knime.enterprise.server.executor.requirements =
# 删除执行者的executor.resources属性
可以通过完全删除环境变量或完全删除knime.ini文件中的属性来删除属性,具体取决于设置属性的方式。或者,也可以通过将环境变量的值或knime.ini文件中的属性的值保留为空来删除该属性。
| 必须重新启动执行程序才能应用更改。 | |
|---|---|
# 执行人要求的行为
执行者只有能够满足为工作流程定义的所有执行者要求,才接受工作。否则,它只会忽略作业。
没有执行者要求的工作将被所有可用的执行者接受。
executor.requirements属性值只需是Executor定义的executor.resources属性值的子集,工作流就可以被Executor接受以执行。
如果没有任何执行者可以满足执行者的要求,则排队的作业将被丢弃。
如果适当的执行器由于其负载太高而无法接受新作业,则新排队的作业将在超时(通常在60秒后)中运行并自行丢弃,请参阅负载限制 (opens new window)。
例: Workflow1执行程序。要求:medium_RAM,两个GPU,Linux Workflow2执行程序。要求:小型RAM,Linux Workflow3执行程序。要求: Executor1 executor.resources:小型RAM,Linux,两个GPU Executor2 executor.resources:medium_RAM,Windows,两个GPU 两个执行者都将忽略Workflow1,并将其丢弃。 工作流程2将被执行者2忽略,并被执行者1接受。 任何可用的执行者都将接受Workflow3。
# CPU和RAM要求
从KNIME Server 4.11开始,可以定义工作流程的CPU和RAM要求。默认情况下,这些要求都被忽略和残疾人,除非默认值中的至少一个com.knime.server.job.default_cpu_requirement或 com.knime.server.job.default_ram_requirement的 KNIME服务器配置文件的选项 (opens new window)设置。
# 设置工作流程的CPU和RAM需求属性
CPU and RAM requirements can be set in the same way as Executor requirements and is described in Setting executor.requirements property for a workflow (opens new window). To set the CPU and RAM requirements the following keywords have been introduced:
cpu=The number of cores needed to execute the workflow. Note, that this value also allows decimals with one decimal place (further decimal places are ignored) in case workflows are small and don’t need a whole core. The default is 0. |
|---|
ram=An integer describing the size of memory needed for execution. The following units are allowed: GB (Gigabyte) and MB (Megabyte). In case no unit is provided it is automatically assumed to be provided in megabytes. The default is 0MB |
In case no CPU or RAM requirement has been set for the workflow the default values com.knime.server.job.default_cpu_requirement and com.knime.server.job.default_ram_requirement defined in the KNIME Server configuration file (opens new window) are used. If both default values are either not set at all or set to 0 the CPU and RAM requirements of workflows are ignored.
# Setting CPU and RAM properties for a KNIME Executor
The Executor detects the available number of cores and the maximum assignable memory automatically at startup.
# Behaviour of CPU and RAM requirements
An Executor only accepts a job if it can fulfill the CPU and RAM requirements that were defined for the workflow. Otherwise, it will ignore the job. If a job gets accepted by an Executor its required CPU and RAM will be subtracted from the available resources until it gets either discarded/deleted or swapped back to KNIME Server. The time a job is kept on the Executor can be changed via the option com.knime.server.job.max_time_in_memory defined in the KNIME Server configuration file (opens new window).
Example:
Workflow1 executor.requirements: cpu=1, ram=16gb
Workflow2 executor.requirements: cpu=1, ram=8gb
Workflow3 executor.requirements: cpu=0.1, ram=512mb
Executor: number of cores: 4, available RAM: 32GB
Workflow1 can be executed 2 times in parallel, since RAM is limiting
Workflow2 can be executed 4 times in parallel, since CPU and RAM is limiting
由于CPU的限制,Workflow3可以并行执行40次
# 执行人预约
随着KNIME Server 4.11的发布,我们引入了保留KNIME执行器专用的可能性。这超出了现有的工作流程固定, (opens new window)因为除非满足某些要求,否则KNIME执行者现在可以拒绝接受作业。
在两个主要用例中,这可能会有所帮助:
- 根据工作流程要求保留执行程序:这可以确保具有某些属性(例如大内存,GPU)的执行程序仅接受标记为需要这些属性的作业。
- 基于单个用户或用户组的可用性要求的执行程序保留:这使您可以保证个人或组的执行资源的可用性。例如,您可以保留KNIME执行器,使其仅接受由特定组的用户发布的作业。
# 保留执行人的前提条件
为了使用Executor保留,需要与工作流固定相同的先决条件。 必须启用分布式KNIME执行器, (opens new window)并且必须安装RabbitMQ (opens new window)。在单执行程序部署中,保留将被忽略。
# 为KNIME执行器设置executor.reservation属性
为了定义工作必须满足哪些要求才能被执行者接受,必须为此执行者设置属性(除了定义执行者提供的用于固定工作流 (opens new window)的资源外)。这可以通过两种方式完成:
在执行器的系统上设置环境变量。变量的名称
KNIME_EXECUTOR_RESERVATION必须为并且值必须为Executor资源的有效布尔表达式。KNIME_EXECUTOR_RESERVATION =资源1 &&资源2 || 资源3在knime.ini文件中设置系统属性,该文件位于Executor的安装文件夹中。该文件包含执行器的配置设置,即Java虚拟机使用的选项。该属性的名称
com.knime.enterprise.executor.reservation必须为并且该值必须为Executor资源的有效布尔表达式。-Dcom.knime.enterprise.executor.reservation = resource1 && resource2 || 资源3
| 如果同时指定了环境变量和系统属性,则它们具有优先级。 | |
|---|---|
# 删除KNIME执行器的executor.reservation属性
可以通过删除环境变量或通过删除knime.ini文件中的属性来禁用该属性,具体取决于该属性的设置方式。或者,可以将环境变量或knime.ini中的属性值设置为空字符串。
| 必须重新启动执行程序才能应用更改。 | |
|---|---|
# 设置工作流程的执行程序保留属性
为各个工作流程设置执行程序保留规则的过程与固定 (opens new window)工作流程的过程相同 。也就是说,通过在KNIME Explorer中右键单击工作流程并打开``属性...''对话框来访问执行保留。
# 执行程序保留的语法和行为
The rule for Executor reservation is defined by a boolean expression and supports the following operations:
resource: valueA resource evaluates to true if and only if the job requirements contain the specified resource (see workflow pinning (opens new window)). |
|---|
&&: r1 && r2Logical AND evaluates to true if and only if r1 and r2 evaluate to true, otherwise evaluates to false. |
||: r1 || r2Logical OR evaluates to true if either r1 or r2 or both evaluate to true, otherwise evaluates to false. |
!: !rLogical negation evaluates to true if and only if r evaluates to false, otherwise evaluates to false. |
user: (user = )Evaluates to true if and only if the user loading the job is ``. Note that the parentheses are mandatory. |
group: (group = )Evaluates to true if and only if the user loading the job is in the specified group. Note that the parentheses are mandatory. |
Note: the usual operator precedence of logical operators applies, i.e. ! has a high precedence, && has a medium precedence and || has a low precedence. Additionally, you can use parentheses, to overcome this precedence, e.g.:
A && B || A && C = A && (B || C)
A KNIME Executor only accepts a job if
- the Executor can fulfill all requirments that the job has, and
- if the job’s resources requirements match the Executor’s reservation rule.
否则,该工作将被执行者拒绝。这也意味着,如果执行者的保留规则中至少定义了一种资源,则没有资源需求的作业将被拒绝。
保留规则中使用的资源应该是执行者提供的资源的子集,否则所有作业都可能会被拒绝,因为执行者将无法满足要求。
如果任何执行者不接受工作,则将其丢弃。如果有执行者愿意接受一项工作,但由于他们的负载太高而无法立即执行,那么新工作将进入超时状态(通常在60秒后)并放弃自身,请参阅负载限制 (opens new window)。
除以外的大多数特殊字符'都允许成为用户,组或资源的一部分。在这种情况下,用户名,组名和资源值必须放在之间',例如:
(用户='knime@knime.com')|| (group ='@ knime.com')&&'Python + Windows'
例:
- 工作流程所需的资源:
- w1要求
large_RAM, Linux - W2要求
large_RAM, GPU - W3要求
Linux - W4要求
Windows - w5不需要任何东西
- w1要求
- 执行官提供的资源和预订规则:
- e1提供
large_RAM, Linux, GPU并保留用于`large_RAM && (GPU || Linux)`` - e2提供
GPU, Windows并保留用于!Linux
- e1提供
- 可能的工作执行
- w1将被e2拒绝(因为e2被保留用于
!Linux),并将被e1接受。 - w2将被e2拒绝(因为e2不提供
large_RAM),并将被e1接受。 - w3将被两个KNIME执行器拒绝(因为e1为保留
large_RAM而e2为保留!Linux),并将被丢弃。 - w4将被e1拒绝(因为e1不提供
Windows)并被e2接受。 - w5将被e1拒绝(因为e1为保留
large_RAM),并被e2接受(因为空需求匹配!Linux)。
- w1将被e2拒绝(因为e2被保留用于
# 执行者团体
随着KNIME Server 4.11的发布,我们引入了将KNIME执行器分组以供专用的可能性。 由于将作业分配到与其需求相匹配的指定KNIME执行器组,因此扩展了执行器保留 (opens new window)。
这可能有用的主要用例是允许您确保具有特定属性(例如大内存,GPU)或基于特定用户和组的作业仅由特定的KNIME执行器组处理。由于只有可能匹配的KNIME执行程序会看到该消息,因此减少了接任务的潜在延迟。此外,它还允许您将KNIME执行器划分为多个逻辑组,以便于维护(例如,涉及扩展)。
# KNIME执行器组的先决条件
为了使用KNIME执行器组,需要与工作流固定相同的先决条件。 必须启用分布式KNIME执行器, (opens new window)并且必须安装RabbitMQ (opens new window)。在单执行程序部署中,将忽略组。
# 创建KNIME执行器组
To define KNIME Executor Groups the following options have to be set in the KNIME Server configuration file (opens new window):
com.knime.enterprise.executor.msgq.names=,,…Defines the names of the KNIME Executor Groups. The number of names must match the number of rules defined with com.knime.enterprise.executor.msgq.rules. Note, that names starting with amqp. are reserved for RabbitMQ. |
|---|
com.knime.enterprise.executor.msgq.rules=,,…Defines the exclusivity rules of the KNIME Executor Groups. The number of rules must match the number of rules defined with com.knime.enterprise.executor.msgq.names. |
# Assigning KNIME Executors to a group
There are the following two ways to assign an Executor to a group.
Setting an environment variable on the system of a KNIME Executor. The name of the variable has to be
KNIME_EXECUTOR_GROUPand the value must be one of the names defined incom.knime.enterprise.executor.msgq.names.KNIME_EXECUTOR_GROUP=DefaultGroupSetting a system property in the knime.ini file, which is located in the installation folder of the Executor. The file contains the configuration settings of the Executor, i.e. options used by the Java Virtual Machine. The name of the property has to be
com.knime.enterprise.executor.groupand the value must be one of the names defined incom.knime.enterprise.executor.msgq.names.-Dcom.knime.enterprise.executor.group=DefaultGroup
| The environment variable has priority over the system property if both are specified. | |
|---|---|
In addition, it is necessary to also specify the resources that are offered by an Executor. The process is the same as described for workflow pinning (opens new window). The list needs to contain at least all elements that are needed to distinguish the Executors within their group (except for rules based on user and/or group membership).
# Setting Executor group properties for a workflow
Setting the KNIME Executor Groups for individual workflows uses the same procedure as for workflow pinning (opens new window). I.e., execution reservation is accessed by right-clicking a workflow in the KNIME Explorer and opening the 'Properties…' dialog.
# Syntax and behaviour of KNIME Executor Groups
The rules for KNIME Executor Groups are defined the same way as for executor reservation (opens new window) with the exception that a group with an empty rule accepts every job. KNIME Server sets up new message queues in RabbitMQ according to the provided groups.
If a workflow is loaded its requirements are considered and matched with the first workflow group for which the job fulfills the rules. Hence, the order of the groups in com.knime.enterprise.executor.msgq.rules may have an impact on which group gets selected. In case no suitable group can be found an error is thrown. Once a job is loaded it is associated with a single selected KNIME Executor Group.
| While Executor reservations are not necessary, the KNIME Executors still have to fulfill the requirements according to workflow pinning (opens new window). | |
|---|---|
Example:
- Resources required by workflows:
- w1 requires
Python, GPU, group=G1 - w2 requires
Python, GPU - w3 requires
Python, Linux - w4 requires
Python, Windows - w5 requires nothing
- w6 requires
huge_RAM
- w1 requires
- Executors groups with the rules:
- eg1 is reserved for
('user=U1' || 'group=G1') && Python && GPU - eg2 is reserved for
Python || GPU - eg3 is reserved for
Python || Windows - eg4 is reserved for
!huge_RAM - eg4 isn’t reserved
- eg1 is reserved for
- Possible job executions
- w1 will be passed to executor group eg1.
- w2 will be passed to executor group e2.
- w3 will be passed to executor group eg2 (because eg2 accepts every job that either has requirement
PythonorGPU). - w4 will be passed to executor group eg2 (because eg2 accepts every job that either has requirement
PythonorGPUand does occur before group eg3). - w5 will be be passed to executor group eg4 (because it doesn’t require
huge_RAM). - w6 will be be passed to executor group eg5 (because it doesn’t match any of the previous groups and eg5 accepts every job).
# Execution lifecycle
During the course of executing (or running) a workflow, there are several things that happen. Most of the time you don’t need to know about this, but sometimes in more complex deployments, or for detailed debugging it may be helpful to understand the lifecycle of a workflow that is executed.
# Workflows, Jobs and Job states
# Workflows
The workflow is the collection of nodes, setup to perform your data analysis task. A workflow will contain all of the relevant (default) settings to perform the analysis. In addition to the settings a workflow may contain some data, e.g. if the workflow has been partially executed locally and then uploaded to the KNIME Server. A more full description of a workflow, and how to create one is available create-your-first-workflow (opens new window)
# Jobs
On the KNIME Server, a Job is created whenever a workflow is executed. A full copy of the workflow is made into a location where other workflow executions can’t interfere with it. For full details see executing-a-workflow-on-the-server (opens new window)
# Job states
Jobs exist in a variety of different states, which are displayed in either the Explorer view of the KNIME Analytics Platform, or the Jobs tab on the AdminPortal. The job states are:
- UNDEFINED - This is the first state of a job, and may be seen in the case where a KNIME Executor cannot communicate with the server due to network issues, or the Executor not having enough free CPU/RAM resources.
- CONFIGURED - The Job has executed to a certain point, and is waiting for user input e.g. waiting for WebPortal page input by the user clicking Next.
- IDLE - With the current configuration of the nodes, no further nodes can be executed. This is either because a scheduled workflow failed, or if the workflow is executed via the Webportal or via REST it might wait for input.
- EXECUTING - Job is currently executing.
- EXECUTED - Job has been executed (may still be in memory, see notes below)
- DISCARDED - Job has been executed and discarded (meaning Executor resources, and server disk space are freed up.)
Note that in addition to the job states there is the In Memory flag. The flag tells us whether the workflow is residing in the Executor memory, or has been swapped back to disk in the KNIME Server Repository. The setting com.knime.server.job.max_time_in_memory documented in KNIME Server configuration file options (opens new window) defines how long a job will remain in memory before being swapped. Additionally, when an Executor is gracefully shutdown then all jobs currently in memory are swapped back to disk. Additionally it’s possible to manually force a job to swap to disk by issuing a REST call via SwaggerUI for Workflows (opens new window) using the job UUID.
# Remote Workflow Editor
# Introduction
The KNIME Remote Workflow Editor enables users to investigate the status of jobs on the server. Whenever a workflow is executed on the KNIME Server, it is represented as a job on the server. This instance of your workflow will be executed on the KNIME Server, which can be helpful in cases where the server hardware is more powerful than your local hardware, the network connection to external resources such as databases is faster, and does not require traversing firewalls/proxies.
# What is the Remote Workflow Editor
The Remote Workflow Editor looks just like your local workflow editor, apart from the fact that it is labelled and the canvas has a watermark to help identify that the workflow is running on the KNIME Server.
Most of the edit functionality that you would expect from editing a workflow locally on your machine is possible. Notable cases where it’s not yet supported are: copying nodes from a local workflow to a remote workflow (and vice-versa), browse dialog for file reader/writer nodes browses the local filesystem rather than the remote filesystem.
# Installation
The Remote Workflow Editor is installed on the KNIME Analytics Platform as part of the KNIME Server Connector extension, and on the KNIME Server it must be installed into each KNIME Executor. Detailed instructions are found below.
# Server setup
If KNIME Server is installed on Windows Server, then you may use the GUI to install the "KNIME Executor connector" from the "KNIME Server Executor (server-side extension)" feature. For Linux servers it is normally easier to use the command line to install the feature. Change to the KNIME Executor installation directory, and use the command:
./knime -application org.eclipse.equinox.p2.director -nosplash \
-consolelog -r +https://update.knime.com/analytics-platform/{version_exe}+ -i \
com.knime.features.gateway.remote.feature.group -d $PWD
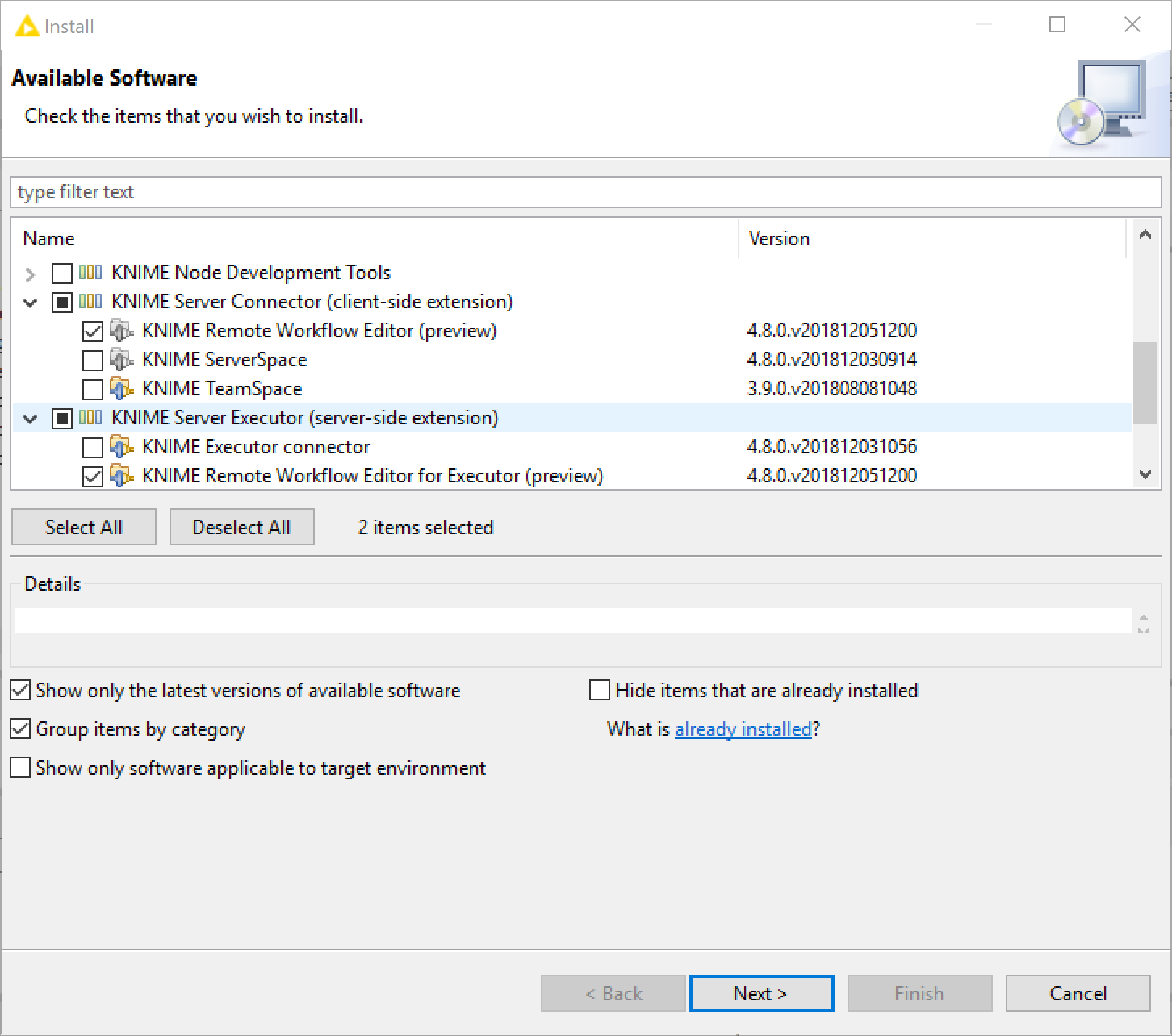
# Analytics Platform setup
The Remote Workflow Editor feature needs to be installed in the KNIME Analytics Platform. Choose File > Install KNIME Extensions, and then select "KNIME Remote Workflow Editor" from the "KNIME Server Connector (client-side extension)" category.
# 用法
可以使用KNIME Analytics Platform通过“打开作业”上下文菜单从驻留在KNIME服务器上的工作流程中创建和打开新作业。看到:
可以通过选择作业并使用“打开作业”上下文菜单来可视化已创建的作业,例如通过使用执行上下文菜单,计划的作业或在WebPortal中启动的作业。看到:
可以查看所有作业(从Analytics Platform执行或通过WebPortal执行),这意味着可以查看节点执行进度,生成的行数/列数以及任何警告/错误消息。
如果工作流在本地KNIME Analytics Platform上,也可以查看和编辑大多数节点的配置设置。当前,不支持在某些文件读取器节点中配置文件路径。
就像在本地工作流程中一样,还可以从工作台中移动,添加和删除节点。
在KNIME Server 4.8版本中,可以通过常规数据视图查看数据。
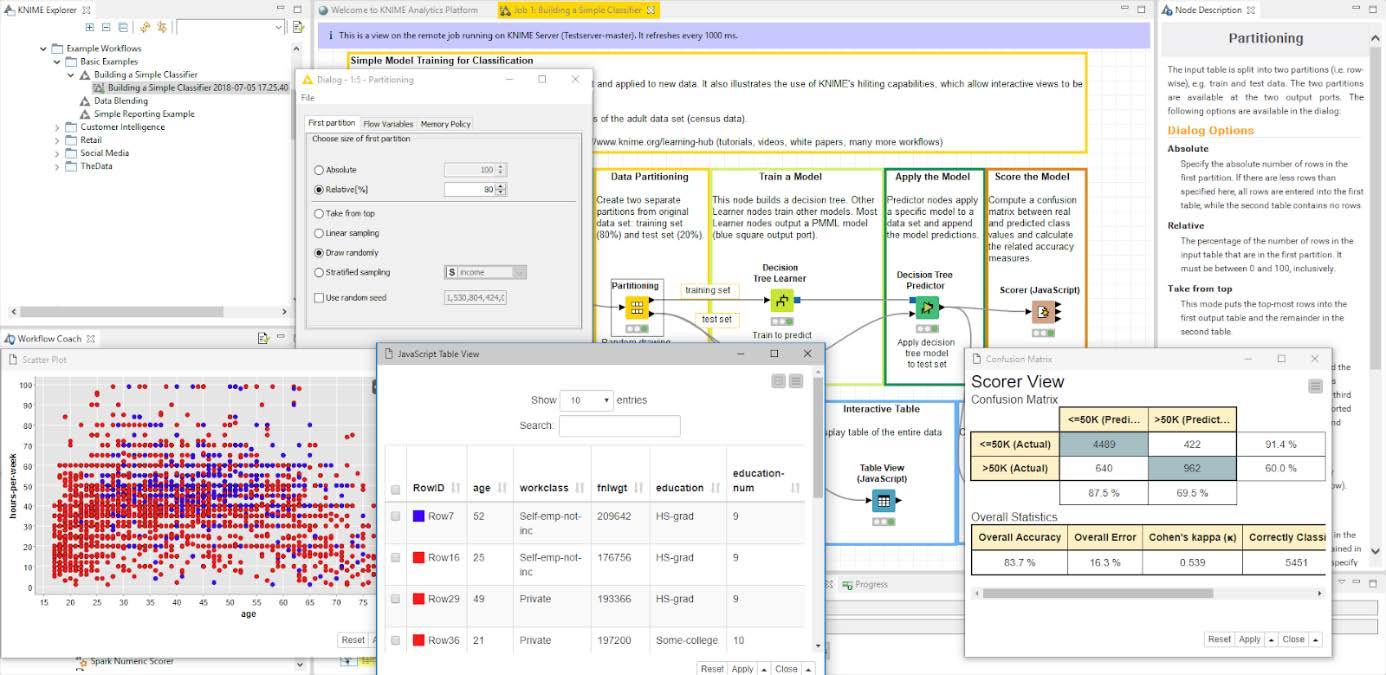
可以使用JavaScript视图来查看数据和视图。
使用KNIME远程工作流编辑器,可以在KNIME服务器上查看和编辑工作流作业。
远程工作流程编辑器首选项允许更改自动刷新间隔,还可以选择取消选中“启用作业编辑”以对所有工作流程强制执行仅查看模式。
您将能够看到当前正在执行的节点,已经执行的节点以及正在排队等待执行的节点。您可以通过将鼠标悬停在相应符号上来查看工作流程中的错误和警告。
在失败的作业中,您可以通过将鼠标悬停在相应的符号上来查看错误和警告消息
# 自定义工作流程教练建议
KNIME Server能够向工作流程教练提供自定义节点建议。为了启用此功能, com.knime.server.repository.update_recommendations_at=必须按照knime-server.config设置表中的说明进行设置。
必须更新KNIME Analytics Platform首选项,以启用其他工作流程指导建议:
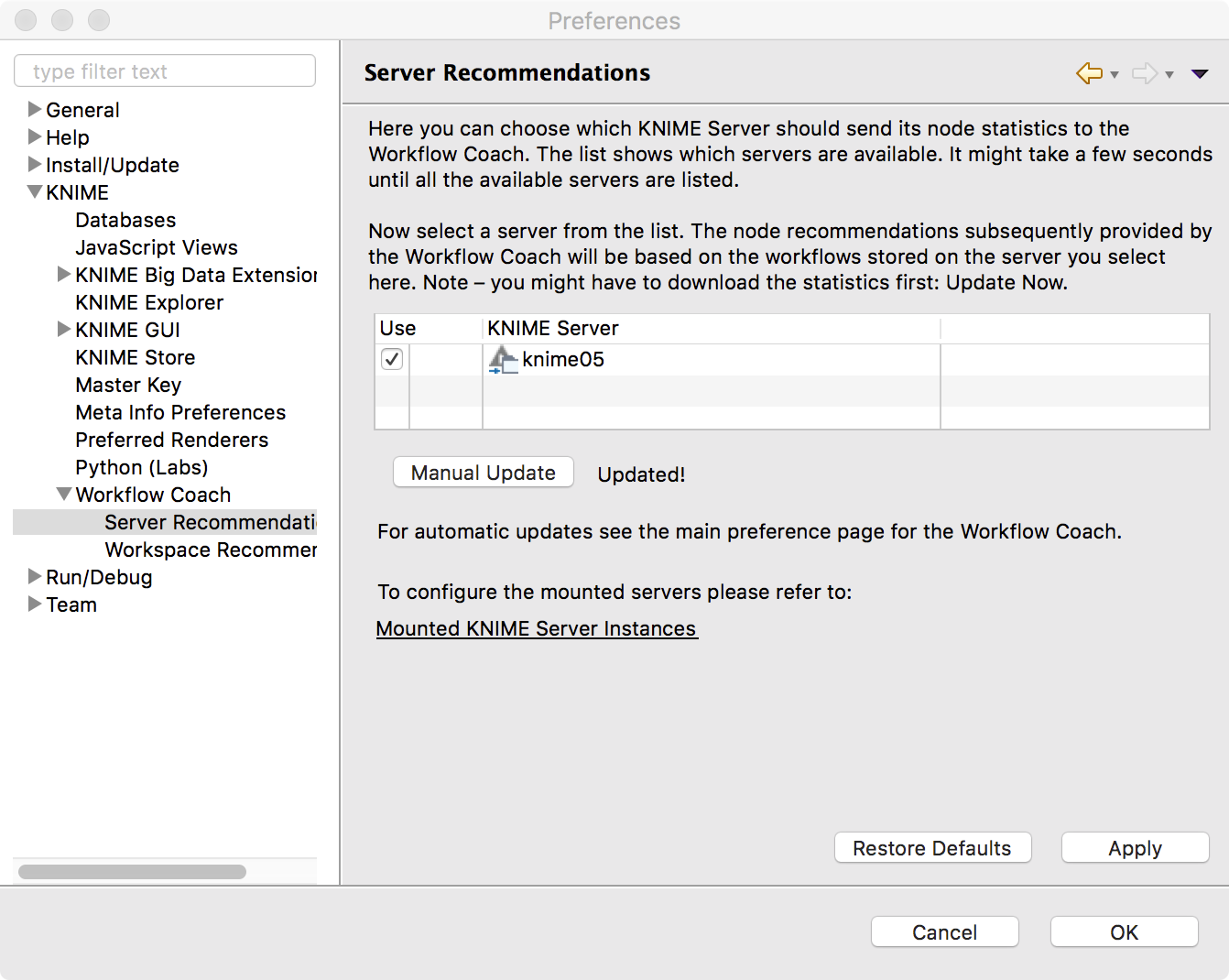
# KNIME Analytics Platform的管理服务:定制
定制允许定义集中管理的:
- 更新网站
- 首选项配置文件(数据库驱动程序,代理设置,Python / R设置等)
KNIME Server allows you to distribute customization profiles to connected KNIME Analytics Platform clients. A profile consists of a set of files that are fetched by the client during startup. The files are copied into the user’s workspace. Files ending with .epf are treated as Eclipse preferences and can be used to override the default preferences which are usually defined by the extension vendors. Settings that an Analytics Platform user has already changed (i.e. which don’t have the default value any more) are not affected. However, the user can choose to "Restore ALL preferences to defaults" via the preference page in the KNIME Analytics Platform. In this case the user is first prompted, then a backup of the preferences file is stored in the /.metadata/knime/preferences-backup.epf, finally, the server-managed settings will replace any preferences with the configured default values. The feature is available to all KNIME Server named-users and additionally to all registered consumers.
# Analytics Platform Customization
The server installer will create a customization template profile in config/client-profiles.template/customizations. It consists of a preference file that contains all available configuration settings (including detailed descriptions) as well as some additional files that may be referenced in the preference file. Please see customizations.epf for details.
# Server-side setup
In order to enable server-managed customization on the server side you have to create one or more subdirectories inside /config/client-profiles. New server installations already come with an example profile that you can use as a starting point. You can have an arbitrary number of profiles. Which profiles are fetched by the client and in which order is defined by settings in the client (see below). If more than one profile defines a preference value, the last profile in the list requested by the client will determine the actual default value. Let’s have a look at an example.
Suppose the config/client-profiles folder on the server has the following contents:
.../config/client-profiles/base/base.epf
org.knime.workbench.explorer.view/knime.explorer.mountpoint=...
org.knime.workbench.ui/knime.maxThreads=4
.../config/client-profiles/base/my-db-driver.jar
.../config/client-profiles/linux/linux.epf
org.knime.workbench.ui/knime.maxThreads=8
org.knime.python2/python2Path=/usr/bin/python2
org.knime.python2/python3Path=/opt/anaconda3/bin/knime-python
.../config/client-profiles/windows/windows.epf
org.knime.python2/python3Path=C:/Anaconda3/bin/knime-python.bat
.../config/client-profiles/windows/my-lib.dll
.../config/client-profiles/windows/my-db-driver.jar
If the client request the profiles "base,linux" (in this order), the default number of threads used by KNIME nodes will be 8. The python paths are set to the correct Linux paths. If another client requests "base,windows" the default number of threads will be 4 (from the base profile) and the Python 3 path will be set to a folder on the C:\ drive. The pre-defined KNIME Explorer mount points will be identical for both clients because the value is only defined in the base profile.
A profile may contain several preferences files. They are all virtually combined into a single preference file for this profile in alphabetical order.
A profile may contain additional resources, for example JDBC driver files. The entire contents of the client-profiles folder including hidden files is sent to the client as a zip file and unpacked into a location in the client workspace. There is no conflict handling for any other files in the requested profiles (e.g. my-db-driver.jar) because they will end up in separate subdirectories on the client and not be processed further.
For further details and an example on how to distribute JDBC driver files go to the Server-managed Customization Profiles (opens new window) section of the KNIME Database Extension Guide (opens new window).
If KNIME Server is running on Linux or macOS then the permissions of files inside profiles are transferred to the clients. This is useful for executable files on Linux or macOS clients, such as shell scripts. If you have such files in your profiles make sure to set the permissions accordingly on the server. KNIME Server’s running on Windows don’t support this feature because Windows file systems don’t have the concept of executable files.
Note that the profiles on the server are accessible without user authentication therefore they shouldn’t contain any confidential data such as passwords.
In order to create preference files for clients, start a KNIME Analytics Platform with a fresh workspace on the desired environments (e.g. Linux, Windows). This ensures that all preferences are set to their vendor defaults. Then change the preferences to your needs and export them via File → Export → KNIME Preferences. Then copy the resulting epf file to the profile folder on the server.
# Variable replacement
It is possible to use variables inside the preferences files (only those files ending in .epf) which are replaced on the client right before they are applied. This makes the server-managed customizations even more powerful. These variables have the following format: ${prefix:variable-name}. The following prefixes are available:
env: the variable is replaced with the value of an environment value. For example,${env:TEMP}will be replaced with/tmpunder most Linux systems.sysprop: the variable is replaced with a Java system property. For example,${sysprop:user.name}will be replaced with the current user’s name. For a list of standard Java system properties see the JavaDoc (opens new window). Additional system properties can be defined via-vmargsin theknime.ini.profile: the variable will be replaced with a property of the profile in which the current preference file is contained in. Currently “location” and “name” are supported as variable names. For example,${profile:location}will be replaced by the file system location of the profile on the client. This can be used to reference other files that are part of the profile, such as database drivers:org.knime.workbench.core/database_drivers=${profile:location}/db-driver.jarorigin: the variable will be replaced with a HTTP response header sent by the server with the downloaded profiles. In addition to standard HTTP headers (which are probably not very useful), the following KNIME-specific origin variables are available:${origin:KNIME-Default-Mountpoint-ID}— the server’s configured default mount ID${origin:KNIME-EJB-Address}— the address used by the KNIME Explorer; see the client profile templates in the repository created by the installer for an example${origin:KNIME-REST-Address}— base address of the server’s REST interface${origin:KNIME-WebPortal-Address}— address of the server’s WebPortal${origin:KNIME-Context-Root}— base path on the server where all KNIME resources are available, usually/knime.
custom: the variable will be replaced by the custom profile provider implementation that is also used to provide the profile location and list.
In case you want to have a literal in a preference value that looks like a variable, you have to use two dollar signs to prevent replacement. For example $${env:HOME} will be replaced with the plain text ${env:HOME}. If you want to have two dollars in plain text, you have to write three dollars ($$${env:HOME}) in the preference file.
Note that once you use variables in your preference files they are not standard Eclipse preference files anymore and cannot be imported as they are.
# Client-side setup
The client has three possibilities to request profiles from a KNIME Server.
Two command line arguments which define the address and the (ordered) list of requested profiles (note that the command line argument and the variable must be separated onto two lines — as seen below):
-profileLocation http://knime-server:8080/knime/rest/v4/profiles/contents -profileList base,linuxBoth arguments must be supplied either directly on the command line or in the
knime.inibefore the-vmargs.Two preference settings in the "KNIME/Customization profiles" preference page. There the user can select a server and then define the ordered list of profiles that he/she wants to apply. Note that this setting cannot be controlled by the server-managed customization profiles. Changes will take effect after the next start.
A custom profile provider defined in a custom Eclipse plug-in. Since this involves writing Java code and is likely only of interest for large-scale installations we cover this approach in the KNIME Server Advanced Setup Guide (opens new window).
The three possibilities are tried in exactly this order, i.e. if one of them provides a server address and a non-empty list of profiles it will be used and all following providers will be skipped.
It’s also possible to provide a local file system folder as the profileLocation on the command line (or in your custom profile provider). The layout of this local folder must be the same as the profiles folder on the server.
# Client customization
Besides the preferences that are exportable by KNIME Analytics Platform there are additional settings that can be added to the preference files to customize clients:
/instance/org.knime.workbench.explorer.view/defaultMountpoint/defaultMountpoints=,,…A comma separated list of default mount points that should be loaded,e.g. LOCAL,EXAMPLES,My-KNIME-Hub. Changes to this list only affects new workspaces, i.e. workspaces which already contain default mount points will still contain them even though only they haven’t been defined here. If this option is absent and defaultMountpoint/enforceExclusion isn’t set to true then all default mount points will be added. The current default mount points are LOCAL, EXAMPLES, and My-KNIME-Hub. |
|---|
/instance/org.knime.workbench.explorer.view/defaultMountpoint/enforceExclusion=If set to true then all default mount point not defined by /instance/org.knime.workbench.explorer.view/defaultMountpoint/defaultMountpoints will be removed on start up. |
/instance/com.knime.customizations/helpContact.buttonText=If set together with /instance/com.knime.customizations/helpContact.address a button with the provided label will occur under Help in KNIME Analytics Platform. Clicking on the button will, depending on the helpContact.address, either open the default mail client or the default browser with the provided address. |
/instance/com.knime.customizations/helpContact.address=Sets the address of the support contact. This option only takes effect in combination with /instance/com.knime.customizations/helpContact.buttonText. |
/instance/com.knime.customizations/documentation.buttonText=Sets the label of the documentation button that can be found under Help in KNIME Analytics Platform. Clicking on the button will open the default browser and navigate to the documentation. If set to - the button will be hidden. |
/instance/com.knime.customizations/documentation.address=Sets the address of the documentation. By default the documentation address points to the KNIME documentation. |
/instance/com.knime.customizations/windowTitle.appendix=Adds the appendix to the window title of KNIME Analytics Platform. |
/instance/com.knime.customizations/updateSite.uris=,,…Adds the provided addresses to the update sites. |
/instance/com.knime.customizations/updateSite.names=,,…The names that are shown under Available Software Sites for the provided update sites of option. Note that the number of names must match the number of provided URIs. |
/instance/com.knime.customizations/updateSite.default.disable=Disables the default added update sites added by KNIME after a fresh installation or update. If a user enables these update sites again they will remain enabled. |
/instance/com.knime.customizations/updateSite.default.forceDisable=Disables the default added update sites added by KNIME after a fresh installation or update. If a user enables these update sites again they will be disabled with the restart of their client. |
# Security considerations
The following section describe some general security considerations for running a KNIME Server. Some of them are active by default, some other require manual configuration based on your specific environment.
# Protecting configuration files
The configuration files must be accessible by the system account running the KNIME Server. However, this account also runs the KNIME Executor which executes the workflows. This means that a malicious workflow can in principle access the server configuration files if the absolute file system paths are known. Therefore, for high security environments we recommend removing write permissions on the configurations files from the system account so that at least the workflow cannot modify them. This includes the following directories and their contained files:
/conf/bin/endorsed/lib/config
# Encrypted communication
Communication between KNIME Analytics Platform and KNIME Server is performed via HTTP(S). By default, both unencrypted communication via HTTP and encrypted communication via HTTPS (SSL) is enabled.
All encryption is handled by Tomcat, see the Tomcat SSL Configuration How-to (opens new window) for full documentation.
# Server configuration
The KNIME Server installer will enable encryption using a generic server certificate that the client accepts. Note that most browsers will issue a certificate warning when you access the KNIME WebPortal via https for the first time. For production it is recommended to add your own certificate as follows:
Obtain a certificate and create a new Java keystore file named
knime-server.jksas described in Tomcat SSL Configuration How-to (opens new window)Replace the
/conf/knime-server.jkswith the keystore file created in the previous step (note: this will replace the generic server certificate)Adjust the
certificateKeystorePasswordof the following “<Connector… />” definition found in/conf/server.xmlto match the password used in the first step:<Connector SSLEnabled="true" compression="on" maxThreads="150" protocol="org.apache.coyote.http11.Http11Nio2Protocol" port="8443" scheme="https" secure="true" server="Apache Tomcat"> <SSLHostConfig protocols="TLSv1, TLSv1.1, TLSv1.2"> <Certificate certificateKeystoreFile="conf/knime-server.jks" certificateKeystorePassword=<your password> type="RSA"/> </SSLHostConfig> </Connector>You can also adjust the port number but you should not change any of the other value unless you understand the implications.
Restart Tomcat.
In case you want to enforce encrypted communication, we suggest to completely disable the unencrypted HTTP connector on port 8080 (by default). Simply remove the line in the server.xml or embed it into an XML comment.
# Client configuration
If you want encrypted connection from KNIME Analytics Platform to KNIME Server, you have to make sure that KNIME accepts the server certificate. If you have a "real" certificate that was signed by a well-known certification authority then you should be safe. If the signing CA is not known to Java you have to add the CA’s certificate to the keystore used by KNIME:
Get the CA’s certificate in PEM format.
Add the CA certificate to the JRE’s keystore file in
`<knime-folder>/jre/lib/security/cacerts`(KNIME Analytics Platform 3.4.3 and older) or
`<knime-folder>/plugins/org.knime.binary.jre.<..>/jre/lib/security/cacerts`(KNIME Analytics Platform 3.5.0 and newer). This is performed with the keytool command that is part of any Java installation (e.g.
//bin/keytool):keytool -import -trustcacerts -alias <ca-alias> \ -file <CA.crt> -keystore jre/lib/security/cacertsYou can choose an arbitrary name for
. Forinsert your CA’s certificate file. The password for the keystore file is “changeit”.
# Disabling the Manager application
The default KNIME Server installation does not add any users with permissions to access the manager application. The Tomcat manager application is not required for the correct functioning of KNIME Server. You may wish to disable the functionality by deleting the manager, host-manager and ROOT directories from your installation. Note that you should not delete the ROOT directory if you chose to install KNIME Server using the context root of ROOT.
# Tomcat shutdown port
The Tomcat shutdown port is accessible on port 8005, which should not be accessible from machines other than localhost. We have renamed the SHUTDOWN command to a random string that is generated at installation time.
You may choose to remove this option completely by finding the following configuration in the server.xml:
<Server port="8005" shutdown="<RANDOMSTRING>">
and changing it to:
# CSRF prevention
Cross-site request forgery (CSRF) is a type of malicious exploit of a website where unauthorized commands are transmitted from a user that the website trusts (see the Wikipedia entry (opens new window) for more technical details). In the context of KNIME Server this means that some other web page issues a (hidden) REST request to KNIME Server using the current user’s active WebPortal session. The user usually doesn’t notice anything but operations are performed with their account. Since version 4.3.4 KNIME Server contains a CSRF protection which prevents any modification requests (e.g. POST, PUT, or DELETE) to REST methods from hosts other than KNIME Server itself.
In case you have internal web pages on other hosts that deliberately perform valid requests you can disable CSRF protection by adding the following line to /conf/Catalina/localhost/knime.xml:
<Parameter name="com.knime.server.rest.csrf-protection" value="false"
override="false" />
# Avoid clickjacking attacks
Clickjacking is also a malicious attempt to trick a user into clicking on something different than perceived, potentially revealing confidential information or taking control of the computer. (See the Wikipedia entry (opens new window) for more technical details). The best option to avoid clickjacking is setting the HTTP header X-Frame-Options to an appropriate value to prevent the WebPortal being embedded in a third party website. In KNIME Server this can be done with a configuration option com.knime.server.webportal.restrict_x_frame_options. The value can be one of DENY, SAMEORIGIN or ALLOW-FROM any_origin_url. See also this article from MDN (opens new window) about more details of the header and available options.
Please note that, if you want to embed the WebPortal on a different website and want this setting to be enabled, you will have to set the value to ALLOW-FROM xxx (where xxx has to be replaced with the URL of the embedding website).
# Hiding server details
By default, Tomcat prints its name and version number on error pages (e.g. if a location entered in the browser does not exist) and in standard HTTP headers. This information can be used by an attacker to target potential security issues for this particular version. Therefore for high security environments it’s recommended to at least hide the server’s version. Fresh installations from 4.5 onwards already hide the version. If you are upgrading from an existing installation, you can apply the following two small configuration changes:
Add a file
/lib/org/apache/catalina/util/ServerInfo.propertieswith the following contents:server.info=Apache Tomcat server.number=8.5.11.0 server.built= Jan 10 2017 21:02:52 UTCOnly the value of “server.info” is shown in error pages and by default includes the version number. The above example only exposes the server’s name.
Modify the `` entries in
/conf/server.xmland add an attribute “server” with “Apache Tomcat” as value:<Connector port="8080" *server="Apache Tomcat"* ... />This change hides the server version in HTTP headers.
You may also choose to set the following parameter in the knime-server.config file. For full details see KNIME Server configuration file options (opens new window):
com.knime.server.webportal.hide_version=true
# Advanced settings
There are a couple more actions you can take to make the server and the application even more secure which we don’t discuss in detail here because they are only useful in special setups. Example are
- Cross-Origin Resource Sharing (opens new window)
- Strict Transport Security (opens new window)
- Content Security Policy (opens new window) (this policy cannot be implemented in Tomcat without writing custom code; see the section about Running behind frontend server (opens new window) for a possible solution)
# Running behind frontend server
In some cases it makes sense to run KNIME Server (Tomcat) behind a frontend server. Examples are:
- Running several KNIME Servers under the same (public) hostname
- Adding custom HTTP headers (e.g. Content Security Policy, see above)
- Reusing existing HTTPS configurations
- Using standard ports (80, 443)
No configuration changes are required on the KNIME Server side, however, the frontend server must ensure that:
- The public hostname is passed to KNIME Server in all HTTP requests. See the example below for details
- The context root is passed to KNIME Server if it differs from the value configured in KNIME Server
- Information about the public protocol (HTTP or HTTPS) is passed onto the KNIME Server.
Otherwise links generated by KNIME Server may point to the internal address which is useless for outside clients and can even expose sensitive information. A sample configuration for Apache HTTPD looks as follows:
<VirtualHost *:443>
ServerName public.knime.server
# Make sure the public protocol is passed to the server;
# not required if internal and external protocol are the same
RequestHeader set X-Forwarded-Proto "https"
# If a different context root than in KNIME Server is used
# then the ProxyPass config should also be changed to reflect this
# n.b. the leading slash is mandatory
RequestHeader set KNIME-Context-Root-Rewrite "/apache-root"
# Ensure that the public hostname is also used in forwarded requests
ProxyPreserveHost On
ProxyRequests Off
ProxyPass /tomee/ejb http://internal:8080/tomee/ejb
keepalive=On nocanon
ProxyPass /knime http://internal:8080/knime
# Optional
ProxyPass /com.knime.enterprise.sketcher.ketcher
http://internal:8080/com.knime.enterprise.sketcher.ketcher
</VirtualHost>
Please note that such advanced setups require detailed knowledge about Tomcat and Apache configuration (or whatever frontend server you are using) and we can only provide limited support.
# Managing access to files/workflows/components
You can assign access permissions to each server item (workflows or workflow groups) to control the access of other users to your workflows and groups.
# The owner
The server stores the owner of each server item, which is the user that created the item. When you upload a flow, copy a workflow, save a workflow job (an executed flow) or create a new workflow group you are assigned to the new item as owner. When a new server item is created, you can set the permissions how you want this item to be available to other users. Later on, only the owner can change permissions on an item.
# User groups
When the KNIME Server administrator defines the users that have access to the KNIME Server, the users are assigned to groups. Groups can be defined as needed — for example one group per department, or per research group, etc. Each user must be in at least one group, and could be in many groups.
You can set a group to be an administrator group (with the configuration option “com.knime.server.server_admin_group=
# Server administrator
Specific users can be set server administrator with a configuration option (com.knime.server.server_admin_users=,,…,) or by assigning them to the administrator group (see section User groups (opens new window)). Server administrators are not restricted by any access permissions. Administrators always have the right to perform any action usually controlled by user access rights. They can always change the owner of an item, change the permissions of an item, they see all workflow jobs (while regular users only see their own jobs) and they can delete all jobs and items.
# Access rights
There are three different access rights that control access to a workflow and two for a workflow group:
# Workflow group permissions
| Read | Allows the user to see the content of the workflow group. All workflows and subgroups contained are shown in the repository view. |
|---|---|
| Write | If granted, the user can create new items in this workflow group. He can create new subgroups and can store new workflows or Shared Components in the group. Also deletion of the group is permitted. |
Note: In order to access a workflow it is not necessary to have read-permissions in the workflow group the flow is contained in. Only the listing of contained flows is controlled by the read-right. Also, a flow can be deleted without write permission in a group (if the corresponding permission on the flow is granted).
Also, in order to add a flow to a certain group, you only need permissions to write to that particular group, not to any parent group.
# Workflow permissions
| Execute | Allows the user to execute the flow, to create a workflow job from it. It does not include the right to download that job, or even store the job after it finishes (storing requires the right to download). |
|---|---|
| Write | If granted, the user can overwrite and delete the workflow. |
| Read | Allows the user to download the workflow (including all data stored in the flow) to its local desktop repository and inspect the flow freely. |
Note: Executing or downloading/reading a flow does not require the right to read in the group that contains the flow. In fact, there is currently no right controlling the visibility of a single flow (there is no "hidden" attribute).
# Access to workflow jobs and scheduled jobs
There are no permissions to be set on a workflow job or a scheduled job. Only the owner — the user that created the job — can see the job in the repository view, and he is the only user that can delete it (besides any server administrator).
In order to store a workflow job as new workflow in the server’s repository, the user needs the right to download the original workflow (the flow the job was created from). (This is a requirement, because the newly created workflow is owned by the user that stores the job — and the owner can easily grant itself the right to download the flow. Thus, if the original flow didn’t have the download right set, the user that is allowed to execute the flow could easily work around the missing download right.)
# "Owner", "Group", and "Other" rights
As the owner of a server item (workflow, shared component or workflow group) you can grant access rights to other users. But you can only assign permissions on a group level, not for particular users.
# Owner rights
The owner can assign permissions to himself to protect a flow from accidental deletion. He can change his own permissions at any time.
# Group rights
The owner of a server item can assign permissions to all users of a specific group. If an access right is granted to a group, all users that are assigned to this group have this right.
# "Other" rights
Permissions can be set to all users that are not the owner and that are not in one of the groups.
Note: Access rights are adding up and can’t be withdrawn — that means, if, for example, you grant the right to execute a flow to "other" users and you define permissions for a certain group of users not including the execute right, these users of that group are still able to execute that flow, as they obtain that right through the "other" permissions.
# Webservice interfaces
# RESTful webservice interface
KNIME Server supports execution of workflows via a REST interface. The entry point for the REST interface is http://server-address/knime/rest/.
The interface is based on a hypermedia-aware JSON format called Mason. Details about the interface, its operations, endpoints and message formats are provided at the following locations (best opened in an internet browser):
http:///knime/rest/_profile/knime-server-doc.xmlfor the general interface andhttp:///knime/rest/v4/_profile/knime-server-doc-v4.xmlfor the 4.x API
(另请参阅服务器返回的所有响应中的“ Link” HTTP标头)。
查询存储库和执行操作的通常起点是
http:///knime/rest/v4/repository/
(请注意结尾的“ /”)。返回的文档还包含指向进一步操作的链接。
# SwaggerUI工作流程
KNIME服务器会自动为KNIME服务器上存在的所有工作流程生成SwaggerUI页面。您可以从KNIME Analytics Platform使用Show API definition上下文菜单项访问该功能 。
单击菜单项将在浏览器中打开该工作流程的SwaggerUI页面。如上节所述,还可以使用REST API浏览到该页面。
# 常见问题
# 始终使用流量变量重置
如果在远程执行对话框中更改了流变量的值,则必须重置流,以便传播新值。在这种情况下,请勿删除执行对话框中的“执行前重置”复选标记。
# 找不到knime.ini文件
如果用于在服务器上执行流的KNIME实例似乎没有在knime.ini文件中指定设置,则服务器可能未找到ini文件:服务器从以下位置获取默认ini文件:与KNIME可执行文件相同的文件夹。如果将包装脚本指定为可执行文件,而该脚本位于安装文件夹之外,则找不到默认的ini文件。在这种情况下,请将ini文件从安装文件夹复制到中/config。
# 服务器启动需要很长时间
在某些情况下,服务器响应Linux系统上的请求可能需要花费一些时间(最多几分钟)。
# 熵不足
这通常是由于Tomcat使用的随机数生成器的熵不足所致。您可以通过指定其他随机数源来解决此问题,该源将提供更快的数字,但随机性也较小:
- 编辑
/conf/catalina.properties。 java.security.egd=file:/dev/./urandom在文件底部添加一行(注意“ /./”)- 重新启动TomEE
# 大量工作
如果KNIME服务器保留大量作业,则可能有必要增加TomEE可以访问的内存量。只需编辑文件setenv.bat(Windows)或setenv.sh(Linux),即可增加-Xmx的值以使当前设置增加一倍。
# 变更日志(KNIME Server 4.11)
KNIME Server 4.11.2 (发布于2020年9月28日)
# 增强功能
- [SRV-3153]-在服务器启动期间检查Tomcat服务器中是否使用了tomee.war(反之亦然)
- [SRV-3154]-更新“社区”安装点以使用OAuth
# Bug修复
- [SRV-3091]-社交工作流存储库不再可用
- [SRV-3135]-邮件会话未正确转发到服务器
- [SRV-3136]-由于-profileLocation,因此无法从命令行更新执行程序
- [SRV-3148]-如果令牌验证失败,身份验证器可能会抛出NullpointerException
- [WEBP-530]-Nuxt路由取决于最终的'/'
- [WEBP-536]-文件上传:旧的Webportal显示带有对象存储路径的文件位置
- [WEBP-541]-仅具有执行权限的工作流无法执行
KNIME Server 4.11.1 (发布于2020年8月26日)
# 增强功能
- [SRV-2952]-将JWT解析错误传播到日志
- [SRV-2979]-禁止在工作流组上载期间丢失有关简单文件的元信息的警告
- [SRV-3001]-将工作流程摘要与作业一起保存
- [SRV-3064]-改善许多工作的资源管理器性能
- [SRV-3100]-允许在“配置选项”中使用knime.system.default
- [SRV-3110]-增加基于本地队列的执行程序中的内存作业最大数量
# Bug修复
- [SRV-2869]-“服务器执行程序”对话框无法缩放
- [SRV-3035]-在“部署到服务器”中选择工作流程组时,“重置工作流程”被选中
- [SRV-3039]-OIDC:身份验证器中的空指针
- [SRV-3054]-通过与服务器的REST连接,看不到禁用时间表的其他字体
- [SRV-3069]-在旧工作流程上修改计划的作业时潜在的死锁
- [SRV-3078] - OAuth: admin rights missing in Analytics Platform
- [SRV-3088] - OpenAPI index page not loaded properly
- [SRV-3095] - Installer does not contain the files to start KNIME Server as service on Windows
- [SRV-3097] - Repository items named 'services' are not accessible any more
- [SRV-3113] - Authentication Tokens of jobs lose their validity after server restart
- [SRV-3117] - Reading files from the server repository randomly fails with 403
- [SRV-3126] - Credentials Configuration isn’t filled with Server Login
- [SRV-3130] - Embedded user database from pre-4.11 installations is not readable any more
KNIME Server 4.11.0 (released July 13, 2020)
# Enhancement
- [SRV-2033] - Dialogs of DB nodes not available in remote workflow editor
- [SRV-2154] - Permissions for scheduled jobs in REST interface
- [SRV-2155] - Permissions for scheduled jobs in KNIME Explorer
- [SRV-2534] - Allow to reserve executors for exclusive use
- [SRV-2562] - Improve message on forbidden symbols in mountID in server installer
- [SRV-2580] - Allow re-connecting to existing jobs after server restart
- [SRV-2600] - Add max core setting to preferences.epf.template
- [SRV-2639] - Provide versions of server components in REST interface
- [SRV-2696] - Enable dynamic port configuration in remote workflow editor
- [SRV-2712] - Executor should retry connections to message queue
- [SRV-2733] - Port for embedded message queue should be configurable
- [SRV-2798] - [OAuth] Webportal landing page when using OIDC
- [SRV-2807] - Improve job logging
- [SRV-2820] - Dialog option to keep or change history when moving/copying workflows
- [SRV-2821] - Add possibility to map JWT claims to groups
- [SRV-2823] - Reuse OAuth Configuration From AuthenticationValve in KNIME Server
- [SRV-2824] - Automatic OIDC endpoint discovery
- [SRV-2830] - Define multiple queues in server config
- [SRV-2871] - Prevent loss of OIDC configuration when war is updated
- [SRV-2904] - Remove Glassfish support from KNIME Server Client
- [SRV-2920] - Add option to force-enable "Create Snapshot"
- [SRV-2921] - Add option to force-enable "Reset Workflow before upload"
- [SRV-2922] - Change default executor starting port
- [SRV-2926] - Installer should set path to embedded queue in executor knime.ini
- [SRV-2927] - Add new template for server managed customizations specific to executors
- [SRV-2928] - Remove preferences.epf.template from installer
- [SRV-2930] - Fix behavior of Use REST option
- [SRV-2932] - Show warning when using EJB mountpoints
- [SRV-2938] - Extract user and group information for executor reservation
- [SRV-2940] - Executor using embedded message queue should get as many core tokens as available
- [SRV-2948] - Make table view chunk size editable and use smaller default value
- [SRV-2958] - Do not send emails during Remote Job Edits
- [SRV-2962] - 'Workflow summary' endpoint for jobs
- [SRV-2963] - Default.epf template should use REST mountpoint
- [SRV-2971] - New REST endpoint with executor information
- [SRV-2977] - Add job IDs to all job related messages
- [SRV-2982] - Executor should have a start script
- [SRV-2985] - Server client should check for EJB support
- [SRV-2988] - Improve UI of EJB warning dialog
- [SRV-3002] - Support String claim as group-mapping-claim
- [SRV-3013] - Allow force-reset of jobs before saving as workflow
- [SRV-3015] - Update KNIME logo on OIDC login page
- [SRV-3026] - Improve error message if no queue can be found due to group restrictions
- [WEBP-454] - New WebPortal with improved layout and design
# Bugfixes
- [SRV-2352] - Improve error message if unexpected logout occurs
- [SRV-2492] - IPv6 addresses are not correctly handled in canonical host name autodetection
- [SRV-2718] - Closing KNIME OAuth Pop-Up (ESC Key) Will Block Port Used For Redirect
- [SRV-2849] - Unexpected Basic Auth Pop-Up When "Opening API Definition" From the AP in the Browser Without an Authenticated Session
- [SRV-2862] - Subnode-execution mode once set in server get’s overwritten with every job update
- [SRV-2874] - Nullpointer Exception in AP when connecting to server stored as OAuth with OAuth disabled
- [SRV-2883] - OAuth redirect page doesn’t show error
- [SRV-2884] - Edit Mount Point Dialog does not remember Authentication Type
- [SRV-2890] - Mount Point Dialog resizes when large error is displayed
- [SRV-2892] - Wrong error message from executor when workflow cannot be loaded
- [SRV-2899] - JavaNullPointer exception when trying to open configuration window of google updater on a remote job view
- [SRV-2908] - Remote Job View does not refresh after an Executor restart
- [SRV-2934] - Wrong error message when loading workflow failed in executor
- [SRV-2941] - Email notification dialog in Call Workflow action advanced options not displayed correctly
- [SRV-2943] - server_logs.zip sometimes contains folders with incomplete executor ID
- [SRV-2967] - Overwriting workflow group via REST removes existing schedules
- [SRV-2990] - Lazily loaded table rows are not updated in port table view (job view)
- [SRV-3025] - Account settings of KNIME server are not applied on runtime
- [SRV-3032] - Workflow pinning/reservation rules dont accept the @ character
- [SRV-3034] - Failure to read updated server config prevents further updates
- [SRV-3044] - Force reset workflow is ignored on temporary copies of workflows
- [SRV-3051] - Unable to enter username in "Edit Mount Point" dialog
- [SRV-3052] - Server sends multiple Status Emails for loops in workflows
- [SRV-3060] - OAuth: NullPointerException when trying to refresh the access token
# Third party software licenses
The KNIME Server software makes use of third-party software modules, that are each licensed under their own license. Some of the licenses require us to note the following:
The following libraries are used and licensed under the CDDL v1.1 (opens new window) and are owned by Oracle. The copyright belongs to the respective owners.
javax.json-1.0.4.jarjavax.json-api-1.0.jarjstl-1.2.jar
The following libraries are used and licensed under the Apache 2.0 license. The copyright belongs to the respective owners.
amqp-client-5.5.0.jaranimal-sniffer-annotations-1.14.jarbcel-5.2.jarbson4jackson-2.9.2.jarcommons-compress-1.15.jarcommons-fileupload-1.3.1.jarcommons-io-2.4.jarerror_prone_annotations-2.0.18.jarguava-23.0.jarhttpclient-4.5.3.jarhttpcore-4.4.6.jarj2objc-annotations-1.1.jarjackson-annotations-2.8.0.jarjackson-core-2.8.11.jarjackson-databind-2.8.11.jarjackson-dataformat-xml-2.8.11.jarjackson-datatype-jdk8-2.8.11.jarjackson-datatype-jsr310-2.8.11.jarjackson-datatype-jsr353-2.8.11.jarjackson-module-jaxb-annotations-2.8.11.jarjavassist-3.21.0-GA.jarje-7.4.5.jarjsr305-1.3.9.jarkeycloak-tomcat-adapter-7.0.0.jarobjenesis-2.6.jarognl-3.0.8.jarorg.osgi.compendium-4.3.1.jarorg.osgi.core-4.3.1.jarqpid-bdbstore-7.0.6.jarqpid-broker-core-7.0.6.jarqpid-broker-plugins-amqp-0-8-protocol-7.0.6.jarrmiio-2.1.0.jarstax-api-1.0.1.jarstax2-api-3.1.4.jarthymeleaf-2.1.4.RELEASE.jartxtmark-0.13.jarunbescape-1.1.0.RELEASE.jarvaadin-client-compiled-7.7.9.jarvaadin-server-7.7.9.jarvaadin-shared-7.7.9.jarvaadin-themes-7.7.9.jarwoodstox-core-5.0.3.jarxmlbeans-2.5.0.jar
The following libraries are used and licensed under the MIT license. The copyright belongs to the respective owners.
jsoup-1.8.3.jarslf4j-api-1.7.25.jar- jquery 2.2.4
- lodash 4.17.4
- react-15.6.2
- react-bootstrap 0.29.5
- react-bootstrap-table 3.3.4
- react-dom 15.6.2
- react-sidebar 2.1.1
The following libraries are used and licensed under the BSD 3-clause license. The copyright belongs to the respective owners.
- Node-forge 0.7.4 (Copyright (c) 2010, Digital Bazaar, Inc. All rights reserved.)
The following libraries are used and licensed under the Do what the fuck you want to public license (opens new window). The copyright belongs to the respective owners.
reflections-0.9.10.jar
# CDDL v1.1
1.定义。1.1。“贡献者”是指创建或为创建修改做出贡献的每个个人或实体。1.2。“贡献者版本”是指原始软件,贡献者使用的先前修改(如果有)以及该特定贡献者所做的修改的组合。1.3。“受保护的软件”是指(a)原始软件,或(b)修改,或(c)包含原始软件的文件与包含修改的文件的组合,在每种情况下均包括其部分。1.4。“可执行文件”是指源代码以外的任何形式的涵盖软件。1.5。“初始开发人员”是指首先根据本许可提供原始软件的个人或实体。1.6。“更大的工作” 指将涵盖软件或其部分与不受本许可条款约束的代码结合在一起的作品。1.7。“许可”是指本文档。1.8。“可许可的”是指无论是在最初授予时还是在随后获得时,都具有在最大可能的范围内授予此处转让的任何和所有权利的权利。1.9。“修改”是指以下任何一种的源代码和可执行形式:A.任何由于对包含原始软件或先前修改的文件的内容进行添加,删除或修改而产生的文件;B.包含原始软件或先前修改的任何部分的任何新文件;或C.根据本许可条款提供或以其他方式提供的任何新文件。1.10。“原始软件” 表示最初根据本许可发布的计算机软件代码的源代码和可执行形式。1.11。“专利权利要求”是指授予人可许可的任何专利中现在拥有或以后获得的任何专利权利要求,包括但不限于方法,过程和设备权利要求。1.12。“源代码”是指(a)进行修改的计算机软件代码的常见形式,以及(b)包含在此类代码中或与之相关的文档。1.13。“您”(或“您的”)是指根据本许可协议行使权利并遵守其所有条款的个人或法人实体。对于法人实体,“您”包括控制您,由您控制或受您共同控制的任何实体。就本定义而言,“控制”是指(a)权力,直接或间接导致通过合同或其他方式指导或管理该实体,或(b)拥有该实体百分之五十以上(50%)的流通股或实益拥有权。2.许可授予。2.1。初始开发人员补助金。根据您是否遵守以下第3.1节的规定并受第三方知识产权索赔的约束,初始开发人员特此授予您全球性,免版税的非专有许可:(a)具有知识产权(专利或商标除外) )由初始开发者授权,可以使用,复制,修改,显示,执行,再许可和分发原始软件(或其部分),进行或不进行修改,和/或作为较大作品的一部分;(b)在因制作,使用或销售原始软件而受到侵犯的专利权利要求中,制作,制作,使用,实践,出售和出售,和/或以其他方式处置原始软件(或其部分)。(c)第2.1(a)和(b)节授予的许可在初始开发人员首先分发或以其他方式使原始软件根据本许可的条款提供给第三方之日生效。(d)尽管有上述第2.1(b)节的规定,但未授予以下专利许可:(1)您从原始软件中删除的代码,或(2)由于以下原因引起的侵权:(i)原始软件的修改,或(ii)原始软件与其他软件或设备的组合。2.2。贡献者补助金。在您遵守以下第3.1节的前提下,并根据第三方知识产权要求,每位贡献者特此授予您全球范围内的免版税,非专有许可:(a)根据知识产权(专利或商标除外),贡献者可在以下时间使用,复制,修改,显示,执行,再许可和分发该贡献者(或其部分)创建的修改,未经修改的基础以及其他修改,作为涵盖软件和/或作为较大作品的一部分;(b)在专利权下,因该贡献者单独,和/或与其贡献者版本(或其组合的一部分)组合,进行,使用或出售而制造,使用,出售,提供,销售,制造和/或以其他方式处置:(1)该贡献者(或其部分)进行的修改;(2)该贡献者所做的修改及其贡献者版本的组合(或此类组合的一部分)。(c)第2.2(a)和2.2(b)节中授予的许可在贡献者首次分发或以其他方式将修改提供给第三方之日生效。(d)尽管有上述第2.2(b)节的规定,但未授予专利许可:(1)对于贡献者已从贡献者版本中删除的任何代码;(2)因以下原因引起的侵权:(i)第三方对Contributor版本的修改,或(ii)该Contributor与其他软件(作为Contributor版本的一部分除外)或其他设备所做的修改的组合;或(3)根据涵盖软件侵犯的专利权利要求,而没有该贡献者所做的修改。3.发行义务。3.1。源代码的可用性。您以“可执行文件”形式分发或以其他方式提供的所有涵盖软件也必须以“源代码”形式提供,并且该“源代码”形式必须仅根据本许可条款进行分发。您必须在分发或以其他方式提供的涵盖软件的源代码形式的每份副本中包含此许可的副本。您必须以可执行文件的形式通知收件人任何此类涵盖软件,以告知他们如何以合理的方式在习惯于软件交换的媒体上或通过媒体获取此类涵盖软件的源代码形式。3.2。修改。您创建或贡献的修改受本许可条款的约束。您表示您相信自己所做的修改是您的原始创作,并且/或者您拥有足够的权利授予本许可所传达的权利。3.3。必要通知。您必须在每个修改中都包含一条通知,以标识您是该修改的贡献者。您不得删除或更改涵盖软件中包含的任何版权,专利或商标声明,或任何归因于任何贡献者或初始开发者的许可声明或任何描述性文本。3.4。附加条款的应用。您不得以任何源代码形式在任何涵盖软件上提供或强加任何条款,以改变或限制本许可的适用版本或本协议下的接收者权利。您可以选择提供保修,支持并收取费用,对涵盖软件的一个或多个接收者的赔偿或责任义务。但是,您只能代表您自己,而不能代表初始开发人员或任何贡献者。您必须绝对清楚地指出,任何此类保证,支持,赔偿或责任义务仅由您自己提供,并且您在此同意赔偿初始开发人员和每个贡献者对于初始开发者或此类贡献者由于以下原因引起的任何责任:您提供的保修,支持,赔偿或责任条款。3.5。可执行版本的分发。您可以根据本许可条款或您选择的许可条款(其中可能包含与本许可不同的条款)分发涵盖软件的可执行形式,前提是您遵守本许可的条款,并且“可执行文件”形式的许可不试图从本许可中规定的权利中限制或更改“源代码”形式中的接收者权利。如果您以不同的许可证以可执行形式分发涵盖软件,则必须绝对清楚地指出,与本许可证不同的任何条款仅由您提供,而不是由初始开发者或贡献者提供。您在此同意赔偿初始开发者和每位贡献者因您提供的任何此类条款而引起的初始开发者或该贡献者的任何责任。3.6。较大的作品。您可以通过将涵盖软件与不受本许可条款约束的其他代码组合来创建较大作品,并将较大作品作为单个产品分发。在这种情况下,您必须确保涵盖软件满足本许可的要求。4.许可证的版本。4.1。新版本。Oracle是最初的许可证管理人,可能会不时发布此许可证的修订版和/或新版本。每个版本都会有一个不同的版本号。除第4.3节中规定的情况外,除许可管理人外,其他任何人均无权修改此许可。4.2。新版本的效果。您可以根据您最初收到涵盖软件的许可版本的条款,始终继续使用,分发或以其他方式提供涵盖软件。如果初始开发人员在原始软件中包含禁止其在任何后续版本的许可下分发或以其他方式提供的通知,您必须根据最初收到涵盖软件的许可版本的条款分发并提供涵盖软件。否则,您还可以根据许可管理人发布的任何后续版本的许可条款,选择使用,分发或以其他方式使涵盖软件可用。4.3。修改版本。当您是初始开发人员并且想要为原始软件创建新许可证时,如果您满足以下条件,则可以创建和使用此许可证的修改版本:(a)重命名许可证并删除对许可证管理员名称的任何引用(除非注意许可与本许可不同);(b)否则,请明确说明该许可包含的条款与本许可有所不同。5.免责声明。根据本许可,按“原样”提供受保护的软件,不提供任何形式的明示或暗示的保证,包括但不限于所保证的无缺陷,可销售,适用于特定情况的担保。 -入侵。有关所涵盖软件的质量和性能的全部风险由您承担。如果任何形式的覆盖的软件都被证明是有缺陷的,则您(而不是初始开发者或任何其他贡献者)应承担任何必要的服务,维修或纠正的费用。本保修免责声明构成本许可的重要部分。除免责声明外,未经许可,不得使用任何涵盖的软件。6.终止。6.1。如果您不遵守此处的条款,并且在意识到违约后的30天内未能解决此类违约,则本许可和本协议授予的权利将自动终止。就其性质而言,在本许可证终止后必须继续有效的规定应继续有效。6.2。如果您针对初始开发者或与之相关的原始开发者或贡献者(原始开发者或贡献者称为“参与者”)主张专利侵权主张(不包括宣告性判决诉讼),则声称参与者软件(即“参与者版本” (如果参与者是原始开发者,则参与者是参与者或原始软件)直接或间接侵犯任何专利,那么,由该参与者,初始开发者(如果初始开发者不是参与者)和本许可协议第2.1和/或2.2节中的所有贡献者直接或间接授予您的任何及所有权利,应在参与者发出通知的60天后终止在该60天的通知期届满之时,将自动有选择地自动进行,除非您在该60天的通知期内,单方面或根据与参与者的书面协议撤回了对该参与者对软件的索赔。6.3。如果您对参加者提出专利侵权主张,声称在发起专利侵权诉讼之前,解决方案(例如通过许可或和解)解决了该专利的情况,则参与者软件直接或间接地侵犯了任何专利,然后在确定任何付款或许可证的金额或价值时,应考虑该参与者根据第2.1或2.2节授予的许可证的合理价值。6.4。如果根据上述第6.1或6.2节被终止,则在终止前由您或任何分销商有效授予的所有最终用户许可(不包括由任何分销商授予的许可)将在终止后继续有效。7.责任范围。在没有任何情况和法律理论的情况下,无论侵权(包括疏忽大意),合同还是其他方式,您,初始开发者,任何其他贡献者,或有偿软件的任何分发者或任何部分的任何供应商应由您对于任何字符的任何间接,特殊,偶发或继发的损害,包括但不限于:对于商誉的损失,停工,计算机故障或故障,或任何及所有其他商业损害或损失,即使已通知当事人此类损害的可能性也是如此。此责任限制不适用于因该方疏忽大意而导致的死亡或人身伤害的责任,而该法律限制仅适用于此。某些司法管辖区不允许排除或限制偶发或继发性损害,因此,此排除和限制可能对您不适用。8.美国政府最终用户。涵盖软件是一个“商业项目”,该术语在48 CFR 2.101(1995年10月)中定义,由“商业计算机软件”组成(该术语在48 CFR§252.227-7014(a)(1)中定义))和“ 本许可应受原始软件中包含的通知中指定的管辖区的法律管辖(除非适用法律另有规定,则适用的法律除外),但该管辖区的法律冲突规定除外。与本许可相关的任何诉讼均应受原始软件所包含的通知中指定的司法管辖区和地点内的法院的管辖,败诉方应承担费用,包括但不限于法院费用和合理的律师费用。费用和支出。明确排除了《联合国国际货物销售合同公约》的适用。规定应以起草者解释合同语言的任何法律或法规均不适用于本许可。您同意在使用,分发或以其他方式提供任何涵盖软件时,您独自负责遵守美国出口管理法规(以及任何其他国家的出口管制法律和法规)。10.索赔责任。在初始开发者和贡献者之间,由于使用本许可下的权利而直接或间接引起的索赔和损害,由每一方负责,并且您同意与初始开发者和贡献者一起公平地分配此类责任。本文中的任何内容均无意或不应视为构成任何责任承担。根据通用开发和发行许可(CDDL)第9部分的通知根据CDDL发行的代码应受加利福尼亚州法律的管辖(法律冲突规定除外)。与本许可有关的任何诉讼均应受加利福尼亚州北部地区联邦法院和加利福尼亚州州法院的管辖,审判地点位于加利福尼亚州圣克拉拉县。GNU通用公共许可证(GPL)第2版,1991年6月版权所有(C)1989,1991自由软件基金会,公司51 Franklin Street,Fifth Floor Boston,MA 02110-1335美国允许所有人复制和分发本文档的逐字记录副本许可文件,但不允许更改。序言大多数软件的许可旨在剥夺您共享和更改软件的自由。相比之下,GNU通用公共许可证旨在确保您自由共享和更改免费软件-确保该软件对其所有用户免费。该通用公共许可证适用于大多数自由软件基金会的软件以及其作者承诺使用该软件的任何其他程序。(其他一些Free Software Foundation软件则由GNU库通用公共许可证覆盖。)您也可以将其应用到程序中。当我们谈论自由软件时,我们指的是自由,而不是价格。我们的通用公共许可证旨在确保您可以自由分发免费软件的副本(如果需要,可以为此服务付费),可以接收源代码,也可以在需要时获得源代码,从而可以更改软件或在新的免费程序中使用它的片段;并且您知道您可以做这些事情。为了保护您的权利,我们需要做出限制,禁止任何人否认您这些权利或要求您放弃这些权利。如果您分发软件副本或对其进行修改,这些限制将对您承担某些责任。例如,如果您分发此类程序的副本(无论是免费还是收费),则必须授予接收者所有的权利。您必须确保它们也可以接收或可以获取源代码。并且您必须向他们显示这些术语,以便他们了解其权利。我们通过两个步骤保护您的权利:(1)为软件提供版权,以及(2)向您提供此许可证,该许可证授予您复制,分发和/或修改软件的法律许可。另外,为了每个作者和我们的保护,我们想确定每个人都知道此免费软件不提供任何保证。如果该软件被其他人修改并继续销售,我们希望其接收者知道他们所拥有的不是原始的,这样,其他人引入的任何问题都不会影响原始作者的声誉。最后,任何免费程序都会不断受到软件专利的威胁。我们希望避免免费程序的再发行者将单独获得专利许可的危险,实际上会使该程序成为专有程序。为避免这种情况,我们已经明确表示,任何专利都必须获得许可,以供所有人免费使用,或者完全未经许可。复制,分发和修改的确切条款和条件如下。复制,分发和修改的条款和条件0。本许可适用于任何包含版权所有者声明的程序或其他作品,声明它们可以根据本通用公共许可的条款进行分发。下文中的“程序”是指任何此类程序或作品,“基于程序的作品”是指该程序或根据版权法的任何衍生作品:也就是说,包含该程序或其中一部分的作品逐字或经过修改和/或翻译成另一种语言。(此后,术语“修改”中包括但不限于翻译。)每个被许可人都称为“您”。除复制,分发和修改之外的活动均不受本许可的约束;它们不在其范围内。运行本程序的行为不受限制,并且仅当程序的内容构成基于程序的工作(与运行程序无关)时,程序的输出才被覆盖。是否正确取决于本程序的功能。1.您可以在收到任何形式的程序源代码时,以任何方式复制和分发逐字逐字副本,但前提是您应在每份副本上显眼并适当地发布适当的版权声明和免责声明;保留有关本许可的所有声明,并且不作任何保证;并向本程序的任何其他接收者提供本许可的副本以及本程序。您可能需要为转移副本的物理行为收取费用,并且可以选择提供保修保护以换取费用。2。您可以修改本程序或本程序的任何部分的副本,从而构成基于本程序的作品,并根据上述第1节的条款复制和分发此类修改或作品,但前提是您还必须满足所有这些条件:a)您必须使修改后的文件带有明显的声明,指出您已更改文件和任何更改的日期。b)您必须使您分发或发布的全部或部分包含本程序或其任何部分的内容或源于本程序或其任何部分的任何作品均按本许可的条款向所有第三方免费获得整体许可。c)如果修改后的程序在运行时通常以交互方式读取命令,则必须使它在开始运行时以最普通的方式进行交互使用,打印或显示公告,其中包括适当的版权声明以及没有保修(或者说您提供保修)的通知,并且用户可以在这些条件下重新分发程序,并告诉用户如何查看副本本许可证。(例外:如果本程序本身是交互式的,但通常不打印此类公告,则不需要基于本程序的作品来打印公告。)这些要求总体上适用于修改后的作品。如果该作品的可识别部分不是从本程序派生的,并且可以合理地视为独立的单独作品,则当您将它们作为单独的作品分发时,本许可及其条款不适用于这些部分。但是,当您将相同的部分作为基于本程序的作品的一部分进行分发时,整个部分的分发必须按照本许可的条款进行,其对其他被许可人的许可权扩展到整个人,进而扩展到每个人。而不管是谁写的。因此,本节无意主张权利或对您完全由您撰写的作品的权利提出异议;相反,其目的是行使基于本程序控制衍生作品或集体作品分发的权利。此外,仅将不基于本程序的其他作品与本程序(或基于本程序的作品)在存储或分发介质上进行汇总,并不会将其他作品归入本许可的范围。3.您可以复制和分发本程序(或基于本程序的作品,根据上述第1节和第2节的条款,以目标代码或可执行格式提供的第2节中的规定),前提是您还执行以下任一操作:a)随附完整的相应机器可读源代码,必须根据这些条款进行分发通常用于软件交换的介质上的上述第1节和第2节;或(b)附有有效期至少三年的书面要约,以不超过您实际执行源代码分发成本的费用向任何第三方提供相应源代码的完整机器可读副本,根据上述第1节和第2节的条款,在通常用于软件交换的媒体上分发;或者,c)随附您收到的有关分发相应源代码的要约的信息。(此替代方法仅适用于非商业性发行,并且仅当您按照上述b小节的要求以目标代码或可执行形式收到程序时,才可使用。)作品的源代码是指制作作品的首选形式对其进行修改。对于可执行文件,完整的源代码表示其包含的所有模块的所有源代码,以及任何相关的接口定义文件,以及用于控制可执行文件的编译和安装的脚本。但是,作为特殊的例外,所分发的源代码不需要包括任何与运行可执行程序的操作系统的主要组件(编译器,内核等)正常分发的任何内容(以源或二进制形式),除非该组件本身附带可执行文件。如果通过提供从指定位置进行复制的访问权限来进行可执行代码或目标代码的分发,则即使没有强制第三方复制源代码,也提供了从相同位置复制源代码的等效访问权限,这算作源代码的分发。源以及目标代码。4.除非本许可明确规定,否则您不得复制,修改,再许可或分发本程序。以其他方式复制,修改,再许可或分发本程序的任何尝试均无效,并且将自动终止您在本许可下的权利。但是,根据本许可证从您那里收到副本或权利的各方,只要其完全遵守要求,就不会终止其许可证。5.由于您尚未签名,因此不需要接受该许可。然而,没有其他授予您修改或分发本程序或其衍生作品的权限。如果您不接受本许可证,这些行为将被法律禁止。因此,通过修改或分发本程序(或基于本程序的任何作品),即表示您接受本许可,并表明您接受复制,分发或修改本程序或基于本程序的作品的所有条款和条件。6.每次您重新分发本程序(或基于本程序的任何作品)时,接收者都会自动从原始许可方那里获得许可,以在遵守这些条款和条件的情况下复制,分发或修改本程序。您不得对接收者行使此处授予的权利施加任何进一步的限制。您不负责强制第三方遵守本许可证。7.如果 由于法院判决或专利侵权指控或任何其他原因(不限于专利问题),对您施加了与本许可条件相抵触的条件(无论是通过法院命令,协议还是其他方式)不能原谅本许可的条件。如果您不能分发以同时满足您在本许可下的义务和任何其他相关义务,那么您可能根本不会分发本程序。例如,如果专利许可不允许所有直接或间接通过您收到副本的人免版税地重新分发本程序,那么您既可以满足它又可以同时满足本许可的唯一方法是完全避免分发该程序。程序。如果本节的任何部分在任何特定情况下均被视为无效或不可执行,则本节的其余部分旨在适用,而本节的整体旨在在其他情况下适用。本节的目的不是诱使您侵犯任何专利或其他财产权索赔或质疑任何此类索赔的有效性;本部分的唯一目的是保护自由软件分发系统的完整性,这是通过公共许可惯例实施的。依靠该系统的一致应用,许多人为通过该系统分发的各种软件做出了慷慨的贡献。由作者/捐赠者决定是否愿意通过任何其他系统分发软件,并且被许可人不能强加该选择。本节旨在彻底阐明本许可证其余部分所导致的后果。8.如果在某些国家(例如,专利或受版权保护的界面)限制了本程序的分发和/或使用,则将本程序置于本许可下的原始版权所有者可以添加明确的地理分布限制,但不包括那些国家/地区。仅在不排除在外的国家或地区内允许。在这种情况下,本许可书包含了限制,就像写在本许可书正文中一样。9.自由软件基金会可能会不时发布通用公共许可证的修订版和/或新版本。这样的新版本将在本质上与当前版本相似,但可能在细节上有所不同以解决新问题或疑虑。每一个版本都有不同的版本号。如果程序指定了适用于本许可证的版本号和“任何更高版本”,则可以选择遵循该版本或自由软件基金会发布的任何更高版本的条款和条件。如果本程序未指定此许可证的版本号,则可以选择自由软件基金会曾经发布的任何版本。10.如果您希望将本程序的某些部分合并到其他发行条件不同的免费程序中,请写信给作者以寻求许可。对于自由软件基金会拥有版权的软件,请写信给自由软件基金会。我们有时为此例外。我们的决定将遵循两个目标,即维护我们的自由软件所有衍生产品的自由状态以及促进软件的总体共享和重用。无担保11.由于本程序免费获得许可,因此在适用法律允许的范围内,本程序没有任何担保。除在编写版权持有人和/或其他各方的书面声明中另有规定外,本程序按“原样”提供,不作任何形式的保证,包括任何明示或暗示的保证,包括但不限于对适销性和适用性的默示保证。 。有关程序质量和性能的全部风险由您承担。如果程序证明是无效的,则您承担所有必要的维修,修理或纠正的费用。12 除非适用法律要求或书面同意,否则在任何情况下,任何版权所有者或任何其可能修改和/或重新分配上述程序的任何其他方均将对您承担赔偿责任,包括任何一般性,特殊性或偶然性因使用或无法使用该程序而造成的继发性损害(包括但不限于数据丢失或数据丢失或您或第三方造成的损失或该程序无法与其他任何程序一起使用,如果已通知此类持有人或其他方可能发生此类损害。条款和条件的终止如何将这些条款应用于您的新程序如果您开发了一个新程序,并且希望它对公众有最大的用途,实现此目标的最佳方法是使其成为免费软件,每个人都可以根据这些条款进行重新分发和更改。这样做,请在程序上附加以下注意事项。将它们附加到每个源文件的开头是最安全的,以最有效地传达保修范围;并且每个文件应至少具有“版权”行以及指向完整通知所在的指针。只需一行即可给出程序的名称,并简要说明其功能。版权(C)<年份> <作者姓名>该程序是免费软件。您可以根据自由软件基金会发布的GNU通用公共许可证的条款重新分发和/或修改它;许可的版本2,或(由您选择)任何更高的版本。分发该程序是希望它会有用,但没有任何担保;甚至没有对适销性或特定用途适用性的暗示保证。有关更多详细信息,请参见GNU通用公共许可证。您应该已经与该程序一起收到了GNU通用公共许可证的副本;如果没有,请写信给Free Software Foundation,Inc.,地址是:51 Franklin Street,Fifth Floor,Boston,MA 02110-1335 USA。此外,还请提供有关如何通过电子邮件和书面方式与您联系的信息。如果该程序是交互式的,则在以交互方式启动时,使它输出这样的简短通知:Gnomovision版本69,作者的版权(C)年名称Gnomovision附带绝对担保;有关详细信息,请输入“ show w”。这是免费软件,欢迎您在某些情况下重新分发它;输入“ show c”以获取详细信息。假设命令“ show w”和“ show c” 应显示通用公共许可证的相应部分。当然,您所使用的命令可能会被称为“ show w”和“ show c”以外的其他名称。它们甚至可以是鼠标单击或菜单项-适合您的程序。如有必要,您还应该让您的雇主(如果您是程序员)或您的学校(如果有的话)签署该程序的“版权免责声明”。这是一个样本;更改名称:Yoyodyne,Inc.在此声明,James Hacker编写的程序“ Gnomovision”(在编译器中通过验证)没有任何版权权益。1989年4月1日,Ty Coon的签署副总裁Ty Coon不允许将您的程序合并到专有程序中。如果您的程序是子例程库,您可能会认为允许将专有应用程序与该库链接会更有用。如果这是您要执行的操作,请使用GNU库通用公共许可证代替该许可证。由Oracle America,Inc.和/或其分支机构分发的某些源文件受以下澄清和GPLv2特殊例外的影响,基于其类路径库的GNU Project异常(称为GNU类路径异常),但仅在Oracle在特定源文件的标头中明确表示“ Oracle将特定文件指定为受Oracle在附带此代码的LICENSE文件中提供的“ Classpath”例外的约束。” 您还应该注意,Oracle在此软件包中包含多个独立程序。其中一些程序是根据自由软件基金会和其他人认为与GPLv2不兼容的许可提供的。例如,该软件包包括根据Apache许可证2.0版获得许可的程序。此类程序是根据其原始许可授权给您的。Oracle通过将Classpath Exception添加到其GPLv2代码的必要部分来帮助您进一步分发此软件包,这使您可以将该代码与未经GPLv2许可的其他独立模块结合使用。但是,请注意,这不允许您在不兼容的许可证下将代码与Oracle的GPLv2许可代码混合,例如,将此类代码剪切并粘贴到也包含Oracle的GPLv2许可代码的文件中,然后分发结果。另外,如果要从其应用到的任何文件中删除Classpath Exception并分发结果,则可能还需要在GPLv2下也许可该分发中的一些或所有其他代码,并且由于GPLv2是与Oracle分发中包含的某些项目的许可条款不兼容,因此,删除Classpath Exception可能会有效损害您进一步分发软件包的能力。谨慎行事,我们建议您在删除Classpath Exception或对此包进行修改之前,先征询开放源代码领域的律师的建议,然后对该包进行重新分发和/或使用第三方软件。CLASSPATH EXCEPTION将该库与其他模块静态或动态链接是基于该库的组合工作。因此,GNU通用公共许可证版本2的条款和条件涵盖了整个组合。作为一个特殊的例外,该库的版权持有者授予您将该库与独立模块链接以生成可执行文件的权限,而不管这些独立模块的许可条款如何,并可以根据您选择的条款复制和分发生成的可执行文件,但前提是您还满足每个链接的独立模块的该模块许可条款和条件。独立模块是不是衍生自该库或基于该库的模块。如果您修改此库,则可以将此例外扩展到您的库版本,但您没有义务这样做。如果您不希望这样做,请从您的版本中删除此异常语句。
# Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
\1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
\2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
\3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
4.重新分配。您可以在满足以下条件的情况下,以任何形式(带有或不带有修改)以源或对象的形式复制和分发作品或其衍生作品的副本:
您必须向该作品或衍生作品的任何其他接收者提供本许可的副本;和
您必须使所有修改过的文件带有明显的声明,表明您已更改文件;和
您必须以您分发的任何衍生作品的源代码形式保留该作品的源代码形式的所有版权,专利,商标和出处声明,但不包括与该衍生作品的任何部分无关的那些声明;和
如果作品包含“注意”文本文件作为其分发的一部分,则您分发的任何衍生作品都必须包括该通知文件中包含的署名声明的可读副本,但不包括与声明的任何部分无关的那些声明。衍生作品,至少应位于以下至少一个位置:在作为衍生作品一部分分发的NOTICE文本文件中;在原始表格或文档中(如果与衍生作品一起提供);或在“衍生作品”产生的显示中,通常在任何时候出现此类第三方通知的地方。注意文件的内容仅供参考,请勿修改许可证。您可以在自己发布的衍生作品中添加自己的归属通知,或者在作品的NOTICE文本的旁边或作为附录,
您可以在自己的修改中添加自己的版权声明,并可以提供其他或不同的许可条款和条件,以供您使用,复制或分发您的修改,或作为任何此类衍生作品的整体,但前提是您必须使用,复制和分发否则,作品应符合本许可中规定的条件。
5.提交文稿。除非您另有明确说明,否则您有意提交给许可人的包括在作品中的任何贡献均应遵守本许可的条款和条件,而没有任何其他条款或条件。尽管有上述规定,本文中的任何内容都不能取代或修改您可能与许可方签定的有关此类贡献的任何单独许可协议的条款。
6.商标。本许可不授予使用许可方的商标名称,商标,服务标记或产品名称的许可,除非在描述作品的来源和复制通知文件内容时合理和惯常使用是必需的。
7.免责声明。除非适用法律要求或书面同意,否则许可方将按“原样”提供工作(每个贡献者均应提供其贡献),而没有任何明示或暗示的保证或条件,包括但不限于任何标题,非侵权,可贸易性或特定目的适用性的担保或条件。您应独自负责确定使用或重新分发作品的适当性,并承担与您行使本许可下的许可有关的任何风险。
8.责任范围。在任何情况下,也没有任何法律理论上的依据,无论是侵权(包括过失),合同还是其他方式,除非适用法律要求(例如故意和严重过失的行为)或书面同意,任何贡献者均应对您承担以下责任:损害赔偿,包括由于本许可或由于使用或无法使用作品而引起的任何性质的任何直接,间接,特殊,偶然或结果性损害(包括但不限于因商誉损失,停工而引起的损害赔偿) ,计算机故障或故障,或任何及所有其他商业性损坏或损失),即使已告知该贡献者此类损坏的可能性。
9.接受保修或其他责任。在重新分发作品或其衍生作品时,您可以选择提供并收取一定费用,以接受与本许可一致的支持,担保,赔偿或其他责任义务和/或权利。但是,在接受此类义务时,您只能代表自己并独自承担责任,不能代表任何其他贡献者,并且仅在您同意赔偿,捍卫每个贡献者并使他们不承担任何责任的情况下,或由于您接受任何此类保证或附加责任而针对该贡献者提出的索赔。
条款和条件的结尾+
# 麻省理工学院执照
特此免费授予获得该软件和相关文档文件(“软件”)副本的任何人无限制使用软件的权利,包括但不限于使用,复制,修改,合并的权利,发布,分发,再许可和/或出售本软件的副本,并允许具备软件的人员这样做,但须满足以下条件:
以上版权声明和本许可声明应包含在本软件的所有副本或大部分内容中。
本软件按“原样”提供,不提供任何形式的明示或暗示担保,包括但不限于对适销性,特定目的的适用性和非侵权性的保证。无论是由于软件,使用或其他方式产生的,与之有关或与之有关的合同,侵权或其他形式的任何索赔,损害或其他责任,作者或版权所有者概不负责。软件
# 新的BSD许可证(三节)
如果满足以下条件,则允许以源代码和二进制形式进行重新分发和使用,无论是否经过修改,都可以:
- 重新分发源代码必须保留上述版权声明,此条件列表和以下免责声明。
- 二进制形式的重新分发必须在分发随附的文档和/或其他材料中复制以上版权声明,此条件列表以及以下免责声明。
- 未经特定的事先书面许可,<公司名称>的名称或其贡献者的名称均不得用于认可或促销从该软件派生的产品。
版权持有者和贡献者按“原样”提供此软件,不提供任何明示或暗示的担保,包括但不限于针对特定目的的适销性和适用性的暗示担保。在任何情况下,数字Bazaar均不对任何直接,间接,偶发,特殊,示例性或后果性的损害(包括但不限于购买替代商品或服务,使用,数据或服务的损失,业务损失)承担责任。 )无论是基于合同,严格责任还是侵权(包括疏忽或其他方式)导致的任何责任理论,无论是基于使用本软件的任何方式引起的,即使已被告知可能存在这种情况。